
QUANTIPHY, desarrollado por Stanford, encontró que los modelos visión-lenguaje siguen dependiendo más de conocimiento memorizado que de lo que realmente ven en video
Un trabajo académico publicado en diciembre pasado, volvió a poner límites a una de las promesas más ambiciosas de la inteligencia artificial contemporánea: su capacidad para comprender el mundo físico con precisión. El paper “QUANTIPHY: Un punto de referencia cuantitativo para evaluar las capacidades de razonamiento físico de los modelos de lenguaje visual”, desarrollado por investigadores de Stanford y UST, presenta un benchmark diseñado para medir si los modelos visión-lenguaje pueden medir propiedades físicas de objetos en movimiento, como tamaño, velocidad y aceleración, a partir de video. Su hallazgo central es incómodo para la narrativa de progreso: los modelos pueden parecer convincentes, pero cuando la prueba exige razonamiento físico cuantitativo, todavía tienden a imponer lo que “creen saber” sobre el mundo en vez de medir con fidelidad lo que realmente ocurre en el video.
La propuesta parte de una crítica a las evaluaciones previas. Según los autores, la mayoría de los benchmarks sobre comprensión física en modelos multimodales han sido cualitativos y basados en preguntas de opción múltiple o respuestas tipo VQA (consiste en responder preguntas en lenguaje natural sobre una imagen). Ese formato, sostienen, no distingue entre errores pequeños y errores enormes: responder 3.1 metros o 31 metros ante un objeto de 3 metros cuenta igual como “incorrecto”, aunque la diferencia física entre ambas predicciones sea radical. QUANTIPHY busca corregir ese problema con una evaluación numérica estandarizada de inferencia cinemática.
El benchmark reunió 569 videos únicos y 3,355 preguntas, organizadas en cuatro configuraciones principales: movimiento 2D o 3D, combinado con un prior físico estático o dinámico. La tarea consiste en darle al modelo un video y un dato previo, por ejemplo, el tamaño o la velocidad de un objeto, para pedirle que infiera otra propiedad física en unidades del mundo real. El objetivo no era que el modelo “describiera” una escena, sino que hiciera una estimación cuantitativa correcta. Es decir midiera bien sobre lo que estaba viendo sin usar datos de entramiento.
Los resultados muestran que esa capacidad sigue lejos de estar resuelta. En la tabla principal del paper, ChatGPT-5.1 (que ya ha sido retirado del mercado) obtuvo el mejor resultado global con 53.1 puntos de MRA, seguido por Gemini-2.5 Pro con 49.6. Entre los modelos abiertos, el mejor fue Qwen3-VL-Instruct-32B, con 46.0. El dato más llamativo es que el promedio humano fue de 55.6, por encima de todos los modelos evaluados. Los autores subrayan que esto es especialmente significativo porque, en teoría, un sistema con acceso exacto a pixeles y coordenadas debería poder superar con claridad a los humanos en este tipo de tareas; sin embargo, los mejores modelos apenas se acercan a ese nivel.
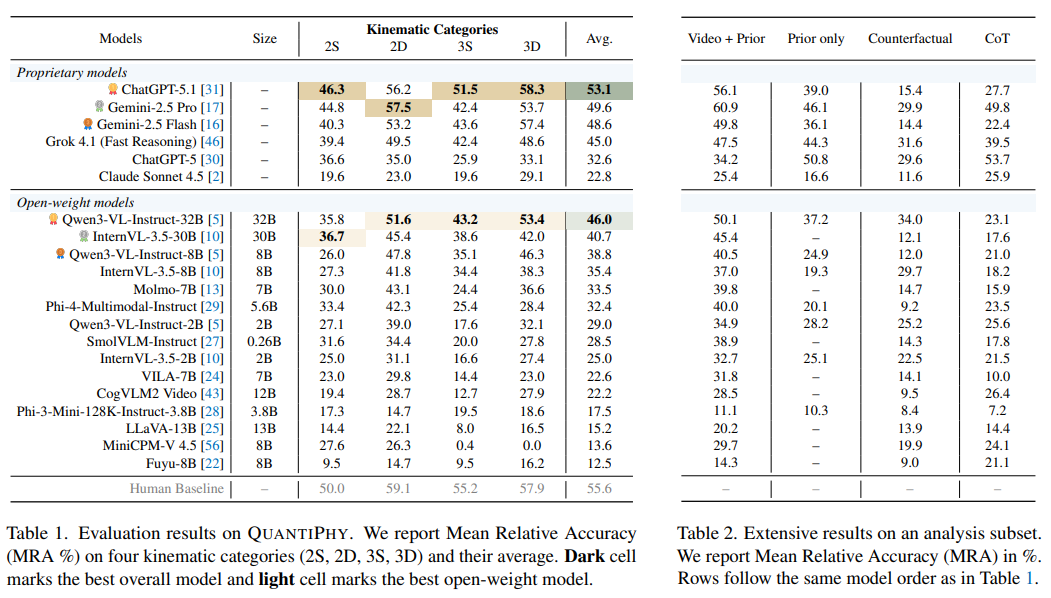
El trabajo también encontró que aumentar la escala del modelo ayuda, pero no resuelve el problema de fondo. En la familia Qwen3-VL, por ejemplo, el rendimiento promedio sube de 29.0 en la versión de 2 mil millones de parámetros a 38.8 en la de 8 mil millones y a 46.0 en la de 32 mil millones. Aun así, esas mejoras muestran rendimientos decrecientes y no cierran la brecha con los mejores modelos propietarios ni con el desempeño humano.
Prefieren memorizar a utlizar datos de contexto visual
Más importante todavía es el diagnóstico sobre cómo “razonan” estos sistemas. En una de las pruebas, los investigadores compararon el desempeño con video + prior frente a una condición con solo prior, es decir, quitando el video pero dejando intacta la descripción textual y el dato físico previo. La caída en rendimiento fue a menudo modesta. En otras palabras, muchos modelos pudieron mantener resultados relativamente altos aun sin mirar la secuencia visual, lo que sugiere que estaban respondiendo a partir de conocimiento memorizado sobre tamaños, velocidades y comportamientos típicos de los objetos, más que a partir de una medición visual fiel.
La prueba más dura fue la de contrafactuales. Los autores alteraron artificialmente el valor del prior físico (multiplicándolo por factores como 0.1, 5, 100 o 700) y observaron si el modelo ajustaba sus respuestas en consecuencia. Si realmente estuviera razonando a partir del prior dado y de la evidencia del video, debería modificar sus estimaciones de manera consistente. Pero no ocurrió así: incluso los mejores sistemas sufrieron caídas enormes en desempeño. El paper concluye que los modelos actuales no son razonadores cuantitativos fieles a la entrada, sino sistemas que tratan los datos visuales y numéricos más como pistas blandas que como restricciones duras.
Uno de los ejemplos más elocuentes del artículo muestra a ChatGPT-5.1 ignorando tanto el video como un prior no estándar para responder con la aceleración gravitacional clásica de 9.8 m/s², simplemente porque ese valor coincide con una expectativa física memorizada. Para los autores, este tipo de error reveló que incluso cuando un modelo parece “entender” una escena, puede estar imponiendo una física estereotipada en lugar de leer lo que realmente ocurre en pantalla.
Ni siquiera los prompts estructurados tipo chain-of-thought resolvieron el problema. En otra parte del estudio, los investigadores dividieron la tarea en pasos intermedios (medición en pixeles, estimación de escala, propiedad del objeto objetivo y conversión a unidades reales) para ver si eso mejoraba la respuesta final. En la mayoría de los modelos, no ayudó; de hecho, el rendimiento empeoró con frecuencia, lo que sugiere que la descomposición explícita del problema tiende a propagar errores intermedios en vez de corregirlos.
El paper sitúa este déficit como un obstáculo serio para aplicaciones más ambiciosas, desde agentes encarnados hasta robótica, conducción autónoma y sistemas que pretendan interactuar con el mundo físico de manera robusta. Si un modelo no puede inferir con fiabilidad cuánto mide un objeto o qué tan rápido se mueve cuando se le da un prior y un video, entonces todavía está lejos de poseer una comprensión física verdaderamente operativa.
La relevancia de QUANTIPHY no está solo en sus resultados, sino en el tipo de pregunta que instala. En un momento en que la industria habla cada vez más de modelos de mundo, physical AI y robótica, este benchmark introduce una exigencia incómoda: no basta con que los sistemas produzcan descripciones convincentes o parezcan entender una escena; tienen que demostrar que pueden vincular observación visual y magnitudes físicas con precisión numérica. El trabajo sugiere que esa transición sigue incompleta. Por ahora, al menos en tareas de cinemática cuantitativa, la IA todavía se parece más a un sistema que adivina con autoridad que a uno que realmente mide el mundo.


