
Alibaba publicó este 14 de abril como código abierto Qwen3.6-35B-A3B, un modelo de mezcla de expertos (MoE) disperso con 35 mil millones de parámetros totales y apenas 3 mil millones activos por inferencia. El lanzamiento llega tras la presentación de Qwen3.6-Plus y consolida una tendencia clara en el equipo Qwen: exprimir al máximo la eficiencia sin sacrificar capacidad.
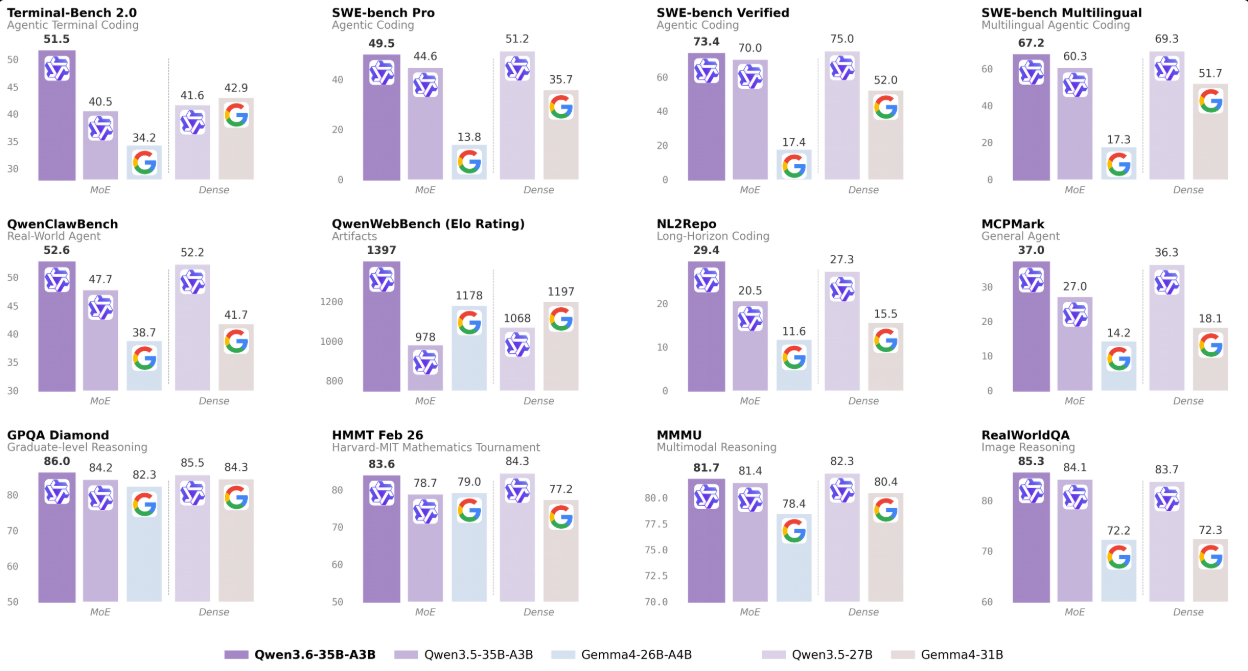
La propuesta central del modelo es su arquitectura dispersa. Al activar solo 3B parámetros en cada pasada, Qwen3.6-35B-A3B opera con el costo computacional de un modelo pequeño, pero con el conocimiento destilado de uno mucho mayor. Los resultados lo respaldan: supera al denso Qwen3.5-27B —que tiene 27B parámetros activos— en varios benchmarks clave de codificación, y mejora drásticamente sobre su predecesor directo, Qwen3.5-35B-A3B, especialmente en tareas de razonamiento y codificación agéntica.
Los números en benchmarks establecidos son contundentes. En SWE-bench Verified alcanza 73.4, frente al 52.0 de Gemma4-31B. En Terminal-Bench 2.0 anota 51.5 contra 42.9. En SWE-bench Pro, 49.5 vs. 35.7.
Multimodal con modos de razonamiento
Qwen3.6-35B-A3B es multimodal por diseño y mantiene compatibilidad con los modos thinking y non-thinking, lo que permite elegir entre razonamiento paso a paso o respuestas directas según el caso de uso. En benchmarks de visión-lenguaje, el modelo iguala el rendimiento de Claude Sonnet 4.5 e incluso lo supera en varias tareas, con resultados especialmente sólidos en inteligencia espacial: 92.0 en RefCOCO y 50.8 en ODInW13.
Una adición relevante para flujos agénticos es la función preserve_thinking, que permite conservar el contenido de razonamiento de turnos anteriores dentro de la conversación —algo particularmente útil cuando el modelo opera como parte de un pipeline multi-paso.
Compatible con Claude Code
Uno de los detalles más llamativos del anuncio es la compatibilidad explícita con Claude Code. La API de Alibaba Cloud Model Studio implementa tanto el protocolo de OpenAI como el protocolo de API de Anthropic, lo que significa que herramientas como Claude Code pueden apuntar a Qwen3.6-35B-A3B con una simple modificación de endpoint, sin cambios en el cliente.
Esto no es un detalle menor: posiciona a Qwen como un backend drop-in para el ecosistema de Anthropic, permitiendo a desarrolladores que ya usan Claude Code aprovechar un modelo open-source autoalojable o de bajo costo en la nube de Alibaba. También es compatible con OpenClaw y Qwen Code para quienes prefieran alternativas en la terminal.
Disponibilidad
El modelo está disponible de tres formas:
- Qwen Studio para uso interactivo inmediato.
- API de Alibaba Cloud Model Studio bajo el alias
qwen3.6-flash. - Pesos abiertos en Hugging Face y ModelScope bajo licencia Apache 2.0, listos para autoalojamiento con SGLang o vLLM.
El contexto nativo soportado es de 262,144 tokens, extensible hasta 1,010,000 tokens.
Perspectiva
Qwen3.6-35B-A3B establece un nuevo punto de referencia para lo que un modelo MoE disperso puede lograr a esta escala. Para equipos que buscan capacidad agéntica y multimodal sin el costo de infraestructura de un modelo denso de 70B+, y que además quieren libertad de despliegue, este modelo es una opción técnicamente sólida. El equipo Qwen anticipa más lanzamientos dentro de la familia Qwen3.6 open-source en las próximas semanas.


