Un estudio sobre sistemas físicos sugiere que los modelos entrenados en representaciones abstractas pueden capturar mejor las reglas de fenómenos dinámicos que aquellos diseñados para reconstruir imágenes cuadro por cuadro.
Durante años, buena parte de la inteligencia artificial ha aprendido a mirar el mundo como una secuencia de señales que debe predecir el siguiente fotograma, o el siguiente cuadro de video. Esa estrategia ha producido avances enormes, pero también deja abierta una pregunta incómoda: predecir cómo se ve algo no significa necesariamente entender cómo funciona.
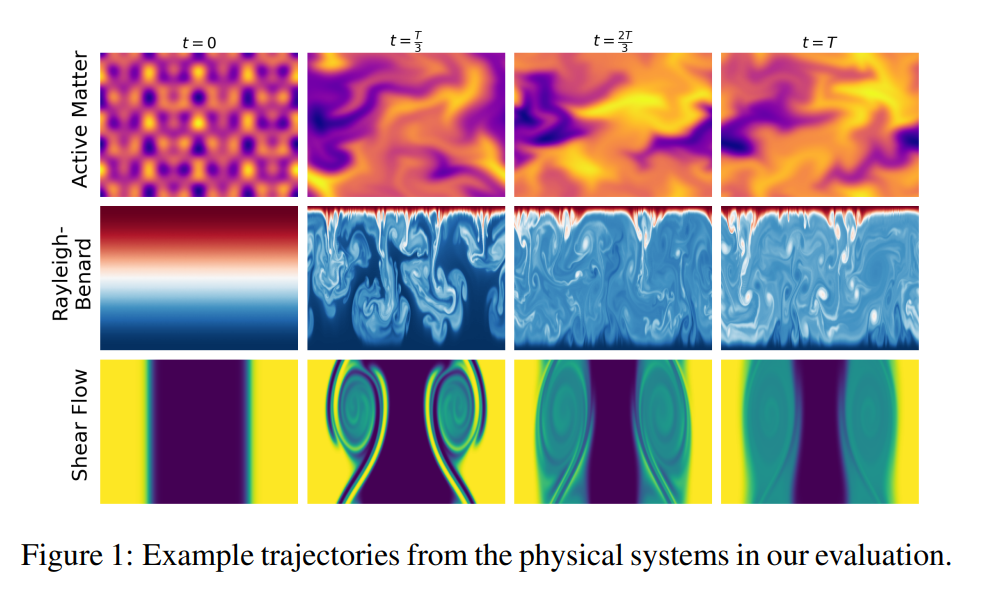
Esa es una de las ideas centrales de un estudio reciente sobre aprendizaje de representaciones para sistemas físicos espaciotemporales. El trabajo, firmado por investigadores de NYU, Flatiron Institute, Polymathic AI y Yann LeCun, analiza si distintos modelos de inteligencia artificial pueden aprender representaciones útiles para entender fenómenos dinámicos como fluidos, convección o materia activa.
El punto de partida es sencillo, pero poderoso. Muchos modelos aplicados a sistemas físicos se entrenan para predecir el siguiente estado de una simulación, por ejemplo, el siguiente cuadro de un fluido en movimiento. Si el resultado se parece visualmente al original, podría parecer que el modelo “entendió” la física del sistema. Pero el estudio plantea una duda: quizá el modelo solo aprendió la apariencia del fenómeno, no las reglas que lo gobiernan.
Para probarlo, los autores no se concentraron únicamente en si el modelo podía reconstruir imágenes o continuar una simulación. Evaluaron si las representaciones internas aprendidas por esos sistemas servían para tareas científicas posteriores, como estimar parámetros físicos que gobiernan el comportamiento del sistema. Esa diferencia es importante: una imagen puede verse correcta, pero una representación útil debería contener información sobre la estructura profunda del fenómeno.
El resultado más interesante es que los modelos que aprenden en espacios latentes [representaciones internas más abstractas] pueden superar a modelos optimizados para predecir a nivel de píxel. Entre esos enfoques aparece JEPA, una arquitectura asociada con una línea de investigación que LeCun ha impulsado durante años: la idea de que la IA necesita construir modelos del mundo, no solo aprender a copiar superficies visibles.
En palabras simples, un modelo entrenado para reconstruir píxeles puede volverse muy bueno imitando cómo se ve una simulación. Pero eso no garantiza que haya capturado variables relevantes, relaciones físicas o patrones que permitan explicar el comportamiento del sistema. En cambio, un modelo que trabaja con representaciones más abstractas puede ignorar detalles visuales secundarios y conservar información más útil para inferir las reglas del fenómeno.
El debate conecta con una pregunta mayor para la inteligencia artificial científica: ¿queremos sistemas que produzcan resultados visualmente convincentes o sistemas que puedan construir representaciones capaces de apoyar descubrimiento, predicción y explicación? En física, biología, clima o materiales, esa diferencia puede ser decisiva. Una IA que “ve” bien no necesariamente entiende el mundo; una IA que representa mejor podría estar más cerca de hacerlo.
El estudio no afirma que estos modelos ya “comprendan” la física como una persona científica. Su aporte es más específico: muestra que la forma en que entrenamos a los modelos cambia el tipo de conocimiento que pueden capturar. Si se les exige copiar píxeles, aprenderán a copiar píxeles. Si se les empuja a construir representaciones más profundas, podrían extraer señales más cercanas a la estructura física del sistema.
La lección va más allá de este paper. En la carrera por crear sistemas de IA más capaces, la pregunta no es solo cuántos datos procesan o qué tan realista es su salida. También importa qué tipo de mundo interno construyen. La próxima frontera de la IA científica quizá no esté en mirar más imágenes, sino en aprender a mirar menos superficie y más estructura.