La compañía presentó MRC, un protocolo desarrollado junto con AMD, Broadcom, Intel, Microsoft y NVIDIA para reducir congestión, sortear fallas en microsegundos y mantener activos los grandes clústeres donde se entrenan modelos frontera.
OpenAI presentó MRC, Multipath Reliable Connection, un nuevo protocolo de red diseñado para mejorar el rendimiento y la resiliencia de las supercomputadoras utilizadas en el entrenamiento de modelos avanzados de inteligencia artificial.
La compañía explicó que el entrenamiento de modelos frontera depende de redes capaces de mover datos rápidamente entre GPUs. En cargas de entrenamiento síncrono, donde miles de procesadores trabajan coordinados “en bloque”, una sola transferencia retrasada puede provocar que parte del sistema quede esperando, desperdiciando ciclos de cómputo y encareciendo el proceso.
El protocolo fue desarrollado durante los últimos dos años en colaboración con AMD, Broadcom, Intel, Microsoft y NVIDIA, y ya se encuentra desplegado en las mayores supercomputadoras con NVIDIA GB200 que OpenAI usa para entrenar modelos frontera, incluidos sistemas vinculados a Oracle Cloud Infrastructure en Abilene, Texas, y las supercomputadoras Fairwater de Microsoft.
A diferencia de las redes tradicionales, donde una transferencia suele seguir una sola ruta, MRC permite repartir paquetes a través de cientos de caminos al mismo tiempo. Esta técnica, conocida como packet spraying, busca evitar puntos calientes de congestión y reducir las variaciones de rendimiento que afectan especialmente a los entrenamientos síncronos.
OpenAI también señaló que MRC puede detectar fallas y rodearlas en escalas de microsegundos. En una red convencional, estabilizar rutas después de una falla puede tardar segundos o incluso decenas de segundos, una diferencia crítica cuando el entrenamiento de un modelo involucra millones de transferencias de datos en cada paso.
Otro cambio importante es el uso de SRv6, una forma de enrutamiento en la que el emisor especifica directamente el camino que debe seguir cada paquete. Con ello, OpenAI busca reducir la dependencia de protocolos dinámicos como BGP dentro de estos clústeres y simplificar el control de red: si una ruta falla, MRC deja de usarla sin esperar a que los switches recalculen caminos.
La compañía aseguró que este enfoque permite construir redes de más de 100 mil GPUs con solo dos niveles de switches Ethernet, en lugar de tres o cuatro niveles como en diseños convencionales. Según OpenAI, esto reduce componentes, consumo eléctrico y costos, además de ofrecer mayor redundancia frente a fallas.
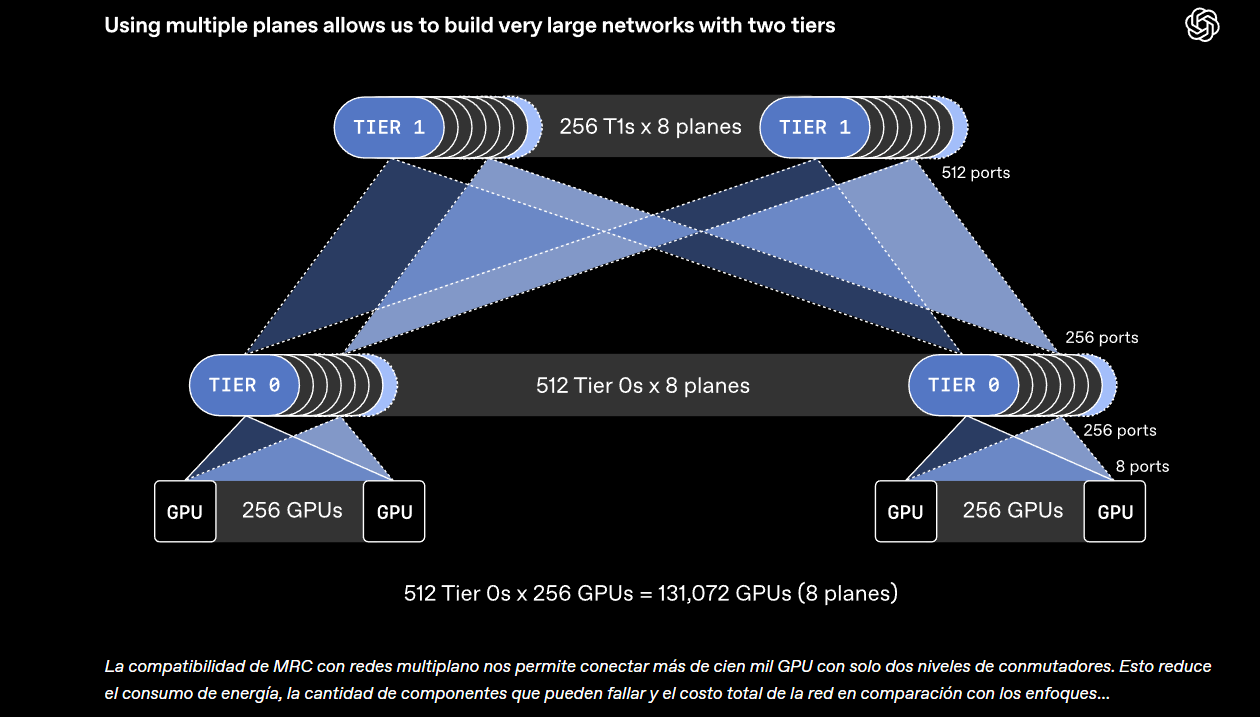
Según OpenAI este sistema les permite construir redes multiplanares de alta velocidad para supercomputadoras con más de 100 000 GPU utilizando solo dos niveles de conmutadores Ethernet. Esto permite una redundancia suficiente para soportar fallos de red, consumiendo menos energía que las redes monoplanares equivalentes de tres o cuatro niveles.
La especificación de MRC fue publicada a través del Open Compute Project, como parte de una estrategia más amplia para convertir ciertas capas de infraestructura de IA en estándares compartidos. Para OpenAI, el diseño de red se ha convertido en una pieza central de la carrera por escalar modelos: no basta con acumular GPUs, también es necesario lograr que trabajen juntas de forma eficiente, estable y resistente a fallas.


