
La startup Subquadratic presentó SubQ 1M-Preview, un modelo que promete procesar grandes volúmenes de contexto con menor costo computacional que los transformers tradicionales. La propuesta apunta a reducir la dependencia de RAG, chunking y otros rodeos técnicos, aunque todavía necesita validación independiente más amplia.
La startup Subquadratic presentó SubQ 1M-Preview, un modelo de lenguaje que promete atacar uno de los límites estructurales de la inteligencia artificial actual: el costo de procesar contextos largos. La empresa describe su arquitectura como fully subquadratic y asegura que, a diferencia de los transformers tradicionales, su cómputo crece de forma lineal conforme aumenta la longitud del contexto.
La promesa es importante porque gran parte de los sistemas actuales de IA no pueden trabajar directamente con archivos, repositorios o colecciones documentales completas sin recurrir a estrategias intermedias. Por eso se usan sistemas como RAG, recuperación previa, fragmentación de documentos, selección de pasajes y diseño de prompts: técnicas que intentan entregar al modelo solo una parte del corpus porque enviar todo el contexto suele ser caro, lento o poco práctico.
Subquadratic afirma que SubQ busca cambiar ese punto de partida. Según la compañía, su modelo permite trabajar con ventanas de contexto mucho mayores, mantener precisión en pruebas de recuperación de información y reducir costos de inferencia. La empresa también anunció tres productos en acceso temprano: una API de contexto completo, SubQ Code para analizar repositorios completos desde línea de comandos, y SubQ Search para búsquedas de contexto largo con velocidad de chatbot.
Entre las cifras presentadas, Subquadratic asegura que SubQ 1M-Preview alcanzó 95% de precisión en RULER 128K, una prueba utilizada para evaluar razonamiento sobre entradas extensas. También afirma que su mecanismo de atención dispersa fue 52 veces más rápido que FlashAttention en una comparación de arquitectura y que requiere 63% menos cómputo. Además, reporta una puntuación de 65.9 en MRCR v2 para el modelo de producción y un resultado de investigación de 83, una evaluación orientada a recuperar y razonar sobre información distribuida en contextos largos.
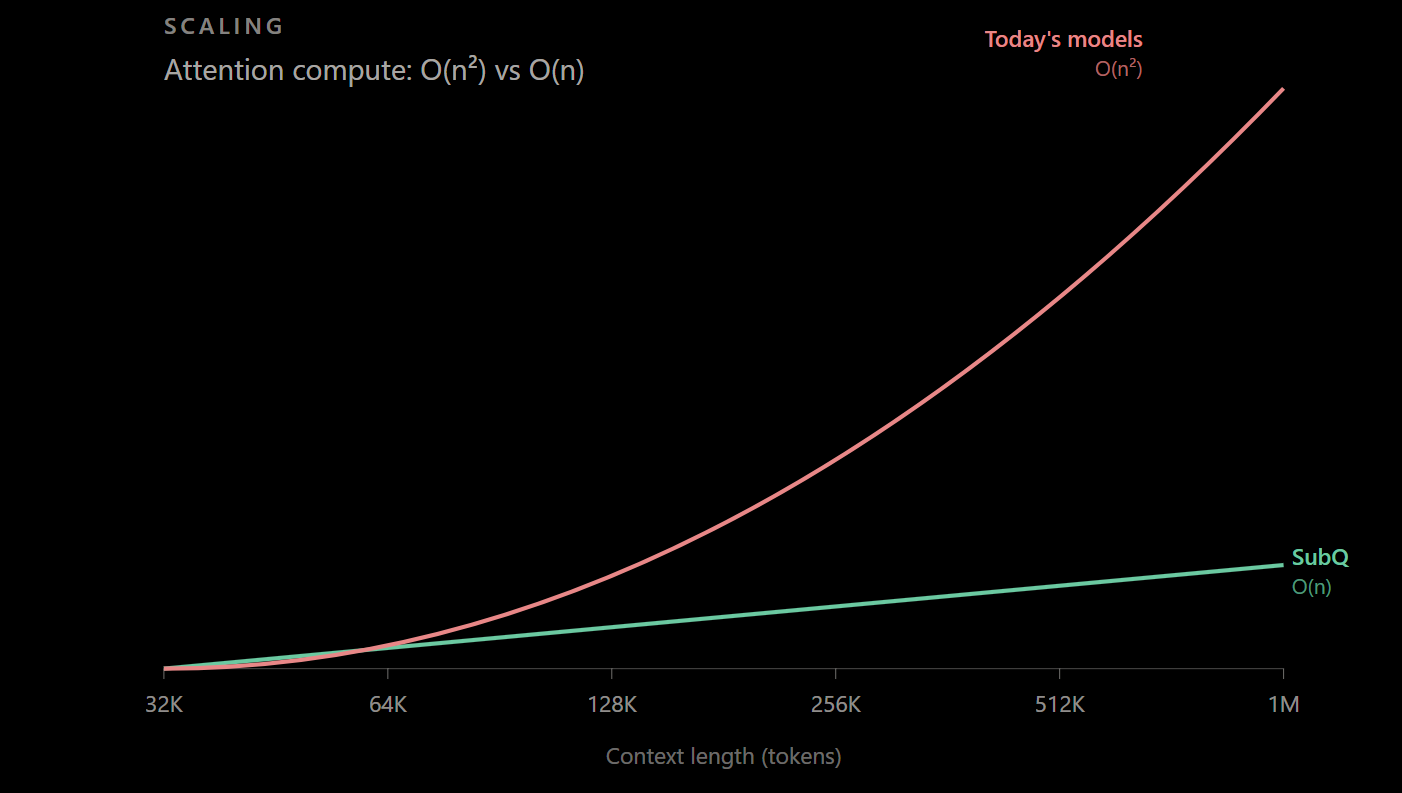
La empresa también sostiene que su arquitectura ha alcanzado resultados de investigación con hasta 12 millones de tokens y que, en ese escenario, reduciría el cómputo de atención casi 1,000 veces frente a otros modelos de frontera. En su sitio principal, Subquadratic presenta a SubQ como un modelo para razonar sobre repositorios completos, historiales largos y estados persistentes de agentes, con una ventana de contexto de 12 millones de tokens en acceso temprano.
Sin embargo, la lectura debe ser cautelosa. Por ahora, SubQ debe entenderse como una apuesta de arquitectura, no como una tecnología ya consolidada por la industria. Aunque la empresa afirma que algunos resultados fueron validados por terceros, aún falta ver pruebas públicas más amplias, uso real en producción, comparaciones reproducibles y análisis independientes sobre calidad, costo, estabilidad y seguridad.
El punto de fondo es que más contexto no equivale automáticamente a mejor comprensión. Un modelo puede recibir millones de tokens y aun así fallar al distinguir lo importante, perder jerarquía, mezclar información irrelevante o arrastrar ruido. La verdadera prueba para SubQ no será solo demostrar que puede leer más, sino que puede seleccionar, razonar y sostener precisión cuando el contexto deja de ser una muestra y se convierte en archivo.
Si su propuesta funciona, podría cambiar el diseño de aplicaciones basadas en IA. Sistemas de análisis documental, agentes de código, memoria persistente, investigación periodística, revisión de expedientes y herramientas de búsqueda podrían depender menos de pipelines complejos de recuperación y más de modelos capaces de procesar grandes cuerpos de información en una sola pasada.
Pero todavía estamos en el terreno de la promesa. SubQ no debe leerse como el fin del RAG ni como una sustitución inmediata de los transformers dominantes. Más bien, marca una dirección relevante en la carrera de la IA: ya no basta con crear modelos más capaces; también se necesita que la memoria, el contexto y la inferencia sean económicamente viables.
En ese sentido, SubQ apunta a una frontera clave: la posibilidad de construir modelos que no solo respondan mejor, sino que puedan trabajar con archivos completos, historiales extensos y sistemas de conocimiento persistente sin que el costo computacional vuelva inviable la aplicación.


