
Cuando se habla del entrenamiento de modelos de lenguaje grande (LLM, por sus siglas en inglés), suele pensarse en una receta simple: meterles cantidades masivas de texto, sumarles mucho poder de cómputo y esperar a que, con suficiente escala, aprendan a responder mejor o como coloquialmente se ha entendido, «predecir la siguiente palabra». Pero entrenar un modelo no consiste solo en darle más datos. También implica revisar constantemente si de verdad está aprendiendo algo útil o si solo se está volviendo bueno para repetir patrones de los ejemplos que ya vio.
Ahí entra una de las partes menos visibles del proceso: la validación. Mientras el modelo entrena, los equipos no solo observan cómo le va con los datos usados para ajustarlo, sino que reservan otro grupo de datos para ponerlo a prueba. La idea es sencilla: si el sistema mejora solo en los ejemplos con los que practica, pero falla cuando se le presentan otros, entonces no está aprendiendo bien. Está memorizando o tomando atajos.
Una de las medidas que se usan para observar eso se llama validation loss. Aunque el nombre suene técnico, la idea no es tan complicada. Es una forma de medir cuánto se equivoca el modelo cuando se le evalúa con datos que no está usando directamente para entrenar en ese momento. Sirve para saber si la mejora que muestra durante el entrenamiento también aparece fuera de los ejemplos que tiene enfrente.
Dicho de otra manera: una cosa es que el modelo baje su nivel de error en los datos con los que está practicando y otra muy distinta es que esa mejora se sostenga cuando se le examina con material aparte. La validation loss funciona como esa revisión externa. No dice todo por sí sola, pero ayuda a detectar si el sistema está generalizando o si solo se está adaptando demasiado bien al material de entrenamiento.
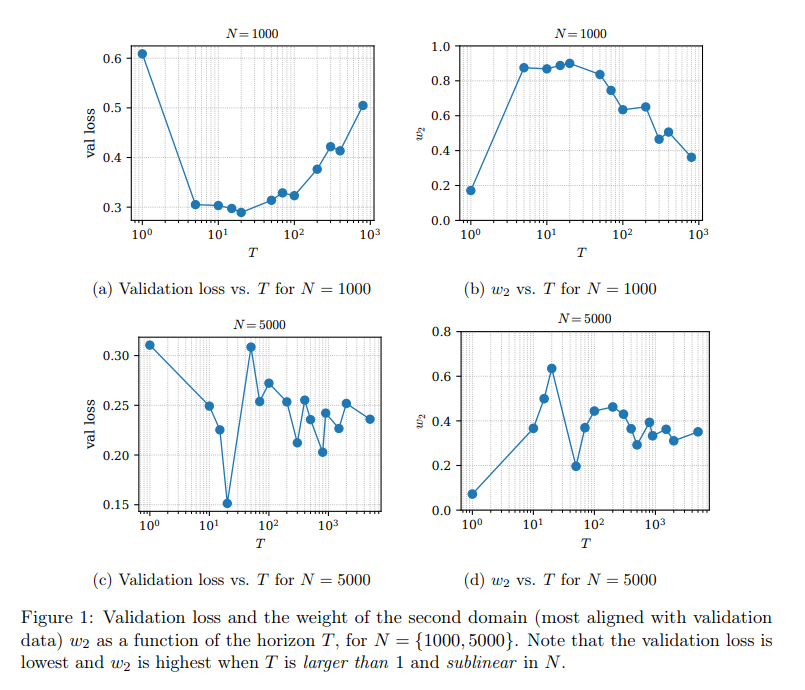
Aquí aparece una pregunta importante: si la validación sirve para saber cómo va el modelo, ¿por qué no usar esa señal de inmediato para cambiar el entrenamiento cada vez que haga falta? Un trabajo reciente de Google Research sugiere que eso también puede salir mal. Según sus resultados, usar demasiado pronto la validación para reconfigurar la mezcla de datos puede empujar el entrenamiento en una dirección equivocada.
La mezcla de datos importa porque los modelos no se entrenan con un solo tipo de información. Un laboratorio puede combinar texto general, programación, matemáticas, ciencia, diálogo o contenido especializado en distintas proporciones. Esa receta influye en el tipo de habilidades que el modelo desarrolla. El problema es que, si esa mezcla se corrige demasiado rápido, a partir de señales todavía inmaduras, el sistema puede terminar persiguiendo mejoras de corto plazo en lugar de avanzar hacia una solución más sólida.
«Menos es más» hasta en los datos
Eso es, en el fondo, lo que plantea una investigación reciente publicada por científicos de Google: no basta con medir el error; también importa cuándo se usa esa medición para intervenir. Una señal puede ser correcta y aun así resultar engañosa si se interpreta antes de tiempo. En vez de ayudar, puede volver miope el proceso de entrenamiento.
Visto así, entrenar un modelo se parece menos a una operación bruta de “más datos, más potencia” y más a una tarea de ajuste fino. No todo depende de cuánto material se le arroja al sistema, sino de cómo se interpreta lo que va mostrando mientras aprende. La validación deja de ser una simple auditoría y se convierte en parte de la estrategia misma del entrenamiento.
Esto también ayuda a responder una inquietud frecuente fuera del mundo técnico: cómo logran las empresas que sus modelos trabajen con datos cada vez más precisos. La respuesta no está en una sola prueba milagrosa, sino en una cadena de controles. Hay filtrado de datos, conjuntos de validación, evaluaciones intermedias, benchmarks y decisiones sobre cuándo conviene intervenir y cuándo es mejor dejar que el proceso madure un poco más.
Por eso la sofisticación del entrenamiento actual no está solo en el tamaño de los modelos o en la cantidad de cómputo que consumen. También está en la capacidad de distinguir entre una mejora real y una señal prematura. En saber cuándo una métrica refleja aprendizaje genuino y cuándo todavía no debe convertirse en una orden para corregir el rumbo.
En la carrera por entrenar modelos cada vez más grandes, la diferencia no siempre la marcará quien tenga más datos, sino quien sepa leer mejor las señales que aparecen durante el aprendizaje. Porque en inteligencia artificial validar no consiste únicamente en medir: también consiste en saber cuándo una señal merece ser creída.


