
La empresa publicó hoy los resultados de una evaluación diseñada para medir capacidades científicas reales en análisis de datos biológicos. Los hallazgos muestran que los modelos más recientes no solo igualan a científicos entrenados: en algunos problemas, los dejan atrás.
Anthropic publicó hoy los resultados de BioMysteryBench, un benchmark de bioinformática desarrollado internamente para medir si sus modelos pueden resolver problemas científicos del mundo real, no ejercicios de laboratorio controlados. El paper, firmado por Brianna, investigadora del equipo de discovery de la compañía, llega en un momento en que la industria debate activamente dónde trazar la línea entre asistente científico y colaborador científico.
Un benchmark distinto: el problema no tiene que ser resoluble por humanos
La mayoría de los benchmarks científicos existentes, tales como: MMLU-Pro, GPQA, LAB-Bench, evalúan conocimiento declarativo o razonamiento estructurado. BioMysteryBench apuesta por algo más cercano al trabajo real: 99 preguntas construidas a partir de datos biológicos crudos o mínimamente procesados (secuenciación de ADN y ARN, proteómica, metabolómica), donde el modelo tiene acceso a un entorno de cómputo con herramientas canónicas de bioinformática, puede instalar paquetes adicionales vía pip o conda, y consultar bases de datos públicas como NCBI o Ensembl.
Lo que distingue al benchmark de sus competidores es una decisión de diseño deliberada: las respuestas correctas se derivan de propiedades verificables de los datos, no de interpretaciones subjetivas de investigadores, lo que permite incluir problemas que los humanos no pueden resolver. En lugar de preguntar «¿qué concluyes de este experimento?», el benchmark pregunta cosas como: ¿de qué organismo proviene esta estructura cristalina? o ¿qué gen fue silenciado en las muestras experimentales comparadas con los controles? Respuestas objetivas, validadas por datos independientes.
El benchmark también es agnóstico al método: no importa cómo llega el modelo a la respuesta, solo que llegue. Eso abre espacio para estrategias creativas que ningún investigador habría seguido.
Los números: paridad con humanos, y en algunos casos, más allá
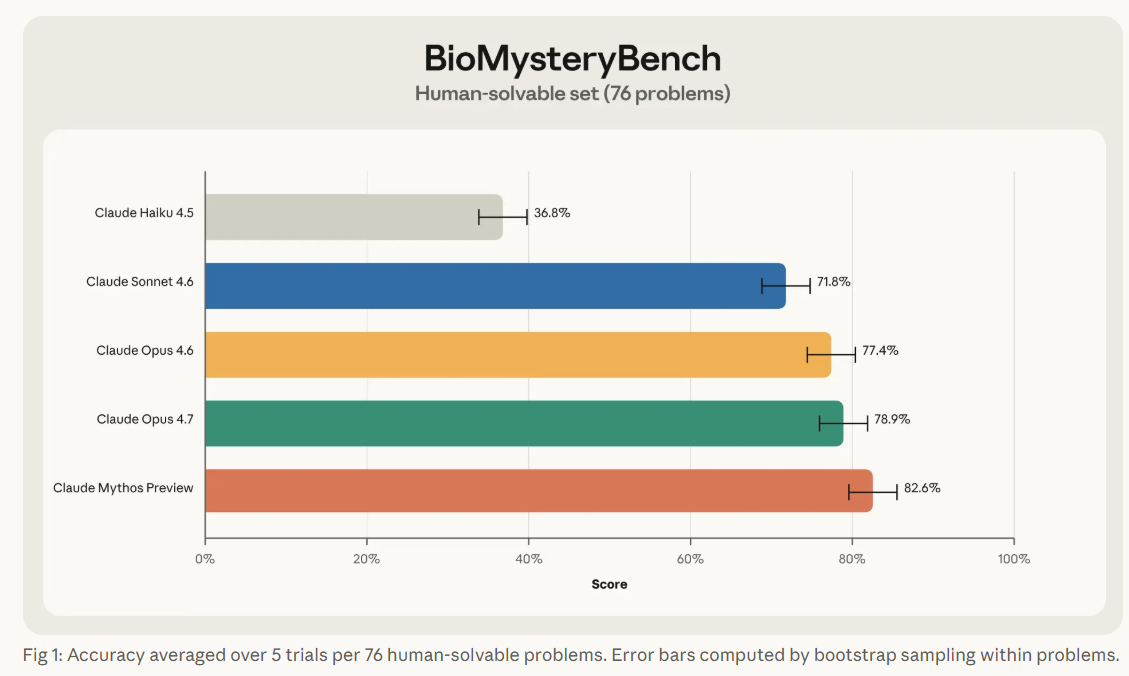
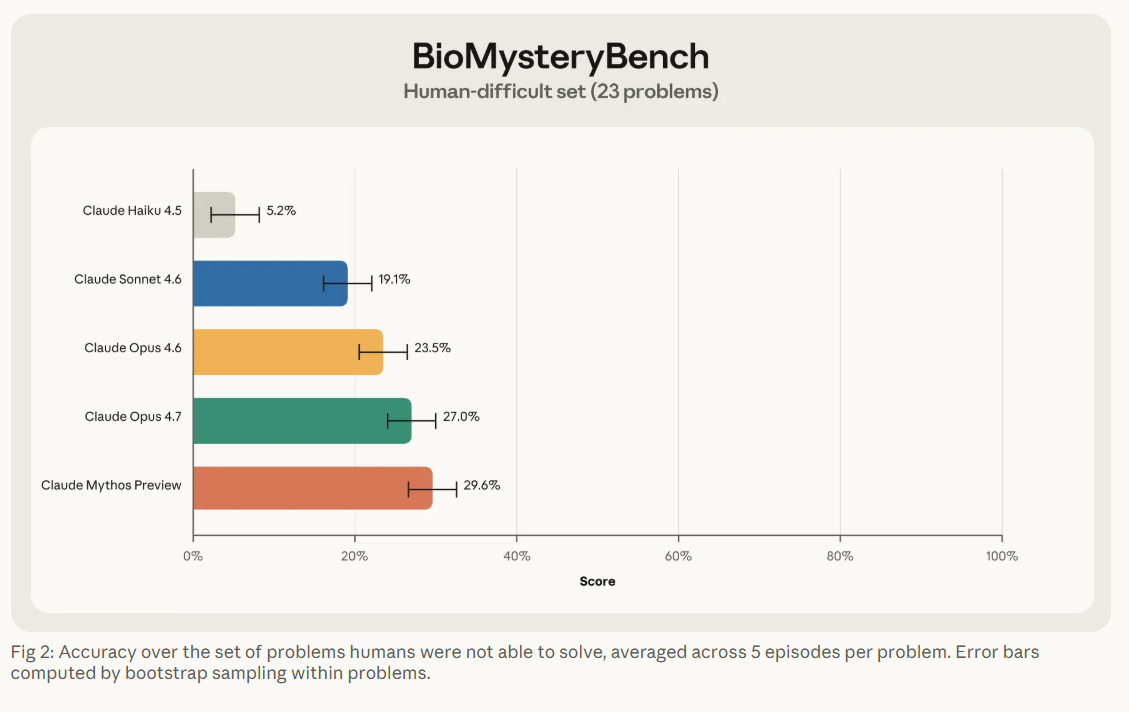
De las 99 preguntas, 76 fueron clasificadas como «resolubles por humanos», al menos un experto del panel de hasta cinco especialistas por pregunta logró responderla correctamente. Las 23 restantes, después de descartar cuatro por errores de formulación, se etiquetaron como «difíciles para humanos»: ningún experto pudo resolverlas.
En el conjunto resoluble, Claude Sonnet 4.6 y los modelos más capaces lograron resolver fracciones significativas de los problemas humano-difíciles, con Claude Mythos alcanzando una tasa de resolución del 30%. En el subconjunto que los expertos sí podían resolver, los modelos más recientes operan en paridad o por encima del rendimiento humano promedio.
Una distinción importante que emerge del análisis de consistencia, realizado en parte por el propio Claude Mythos, es la diferencia entre «resolver» y «saber resolver». En los problemas resolubles por humanos, Opus 4.6 mostró un patrón fuertemente bimodal: el 86% de los problemas que resolvía los resolvía al menos 4 de cada 5 intentos. En los problemas difíciles para humanos, esa cifra colapsa al 44%, y la proporción de victorias «frágiles», resueltas solo 1 o 2 veces en 5 intentos, sube del 9% al 44%. La brecha de precisión es real, pero la brecha de fiabilidad debajo de ella es la historia más interesante sobre dónde está realmente la frontera de capacidad.
Cómo lo hace: conocimiento masivo y triangulación de evidencia
El análisis de transcripciones de Opus 4.6 identificó dos estrategias recurrentes. La primera es lo que los investigadores llaman «know-it-all»: tareas que requerirían que un experto humano corriera un meta-análisis o conectara múltiples bases de datos, Opus las resolvió directamente combinando su conocimiento interno de mecanismos y ontologías con análisis en vivo. Es decir, el modelo sintetiza literatura implícita en su entrenamiento sin necesidad de buscarla explícitamente.
La segunda estrategia es más interesante desde el punto de vista epistémico: cuando el modelo no está seguro de una respuesta, prueba múltiples métodos distintos para resolver el problema y elige la respuesta en la que convergen varios enfoques. Es, en esencia, triangulación de evidencia, algo que los buenos científicos hacen, pero que los modelos de lenguaje rara vez implementaban de forma sistemática.
También se documentó el caso contrario: al menos una vez, el conocimiento previo del modelo fue su perdición. Ante un dataset que contradecía lo que el modelo «sabía» de su entrenamiento, confió en la generalización en lugar de en los datos. Una advertencia relevante para cualquiera que quiera usar estos sistemas en investigación real.
Convergencia con trabajo externo
Mientras Anthropic finalizaba la publicación, Genentech y Roche lanzaron CompBioBench, un benchmark independiente de 100 tareas de biología computacional construido con datos sintéticos y metadatos depurados. Los resultados se alinean: Claude Opus 4.6 alcanza el 81% en el total y el 69% en las preguntas más difíciles, reforzando que los modelos de frontera son ya colaboradores genuinamente útiles para investigación bioinformática. La convergencia entre evaluaciones independientes diseñadas con criterios similares es exactamente el tipo de señal que la comunidad necesitaba.
¿Qué sigue?
BioMysteryBench está disponible públicamente en Hugging Face. Anthropic invita a la comunidad a enviar benchmarks propios, casos de uso innovadores e interacciones con IA que hayan reconfigurado lo que parece posible en su campo. El email de contacto es scienceblog@anthropic.com.
El benchmark tiene una limitación honesta que sus autores reconocen sin rodeos: para los problemas que ni humanos ni modelos han resuelto, nunca se puede saber con certeza si son imposibles o simplemente muy difíciles. Esa ambigüedad, dicen, es también parte del atractivo: un modelo con mayor capacidad científica podría ser el primero en resolver un problema que nadie, humano o máquina, ha podido resolver antes.


