Una de las frases más repetidas sobre la inteligencia artificial generativa afirma que los modelos de lenguaje “solo predicen la siguiente palabra”. La afirmación contiene una parte verdadera, pero usada como explicación total se vuelve engañosa. Los modelos generativos producen secuencias mediante predicción probabilística de tokens; sin embargo, esa operación no ocurre sobre un diccionario ni sobre una lista plana de palabras. Ocurre dentro de una arquitectura entrenada para construir representaciones internas, ponderar relaciones contextuales y transformar esas representaciones a través de múltiples capas antes de calcular una continuación probable.
La primera precisión es terminológica: los modelos no predicen exactamente “palabras”, sino tokens. Un token puede ser una palabra, un fragmento de palabra, un signo, un espacio o una unidad de código. La tarea local del modelo consiste en estimar, dado un contexto previo, qué token puede continuar la secuencia. Pero esa descripción solo nombra el mecanismo inmediato de generación. No explica qué estructuras internas debe aprender el modelo para hacerlo bien.
Si la IA solo eligiera palabras probables de forma superficial, bastaría con un diccionario, una arquitectura neuronal y una biblioteca como PyTorch o TennsorFlow para producir conversación significativa. Pero un diccionario no contiene relaciones contextuales, ambigüedad pragmática, referencias, estilo, género textual, inferencias ni continuidad argumentativa. Puede registrar que “banco” tiene varios significados, pero no puede activar de manera flexible el sentido adecuado en “banco central”, “banco del parque” o “banco de datos”. Esa diferencia es crucial: un modelo de lenguaje no aprende únicamente palabras; aprende regularidades de uso.
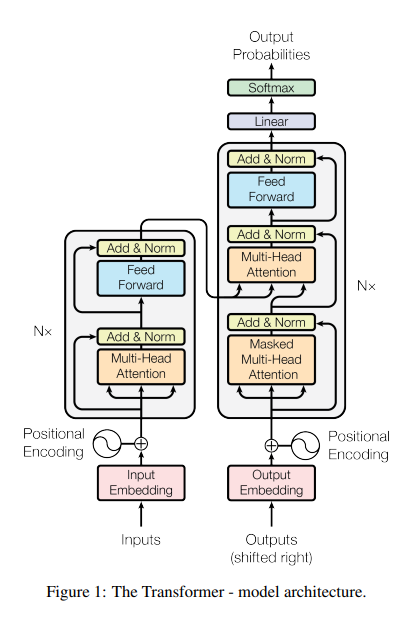
El desarrollo de los Transformers permitió procesar secuencias mediante mecanismos de atención, es decir, mecanismos capaces de ponderar relaciones entre distintas partes del contexto. En Attention Is All You Need, Vaswani et al. propusieron una arquitectura basada exclusivamente en atención, sin recurrencia ni convoluciones, que mostró resultados superiores en tareas de traducción automática y abrió el camino para los modelos de lenguaje contemporáneos.
Arquitectura Transformer
La arquitectura de un Transformer está dividida en dos grandes bloques: el codificador y el decodificador.
En el lado que recibe los inputs, es decir, la secuencia de entrada, los elementos pasan por una capa de input embedding, que convierte los tokens en vectores numéricos. Después se les suma una codificación posicional, porque el Transformer no procesa las palabras de manera secuencial como una red recurrente; necesita una señal adicional para saber el orden de los tokens dentro de la frase.
Luego, la información entra al bloque del encoder, que se repite varias veces. Cada bloque contiene dos partes principales: una capa de multi-head attention y una red feed forward. La atención multi-cabeza permite que cada token observe distintos tokens de la misma secuencia y calcule cuáles son relevantes para construir su representación contextual. Después, la red feed forward transforma esas representaciones de manera independiente para cada posición. Entre estas capas aparecen conexiones de Add & Norm, que combinan la entrada original con la salida de cada subcapa y normalizan el resultado para estabilizar el entrenamiento.
El lado del decoder recibe los outputs desplazados, es decir, la secuencia de salida parcial, usada durante el entrenamiento para predecir el siguiente token. Igual que en el encoder, esos tokens pasan por un output embedding y por una codificación posicional.
El decoder también se repite varias veces, pero tiene una estructura más compleja. Primero usa una capa de masked multi-head attention. Esta atención está “enmascarada” para impedir que el modelo mire tokens futuros. Es decir, cuando predice una palabra, solo puede usar las palabras anteriores, no las que todavía no debería conocer.
Después aparece otra capa de multi-head attention, que conecta el decoder con la salida del encoder. Esa parte permite que el modelo atienda a la información de entrada mientras genera la salida. Por ejemplo, en traducción automática, el decoder usa esa atención para decidir qué partes de la frase original son relevantes al producir cada palabra traducida.
Finalmente, el decoder pasa por una red feed forward, de nuevo acompañada por conexiones Add & Norm. Al final, la salida del decoder entra a una capa linear y luego a una función softmax, que convierte los valores del modelo en una distribución de probabilidades sobre los posibles tokens siguientes.
En términos simples, el Transformer no genera texto consultando un diccionario palabra por palabra. Primero convierte los tokens en representaciones vectoriales, les añade información de posición, calcula relaciones contextuales mediante atención, transforma esas representaciones en varias capas y finalmente produce probabilidades para el siguiente token.
La atención no equivale a comprensión humana, pero sí permite algo técnicamente decisivo: que el modelo no trate cada token como una unidad aislada. En lugar de leer una secuencia como una fila plana de signos, el sistema calcula relaciones internas entre elementos del contexto. Esto le permite estimar qué partes de una instrucción, una frase o una conversación son relevantes para producir la siguiente salida.
La Geometría da sentido
La segunda precisión es que los modelos trabajan con representaciones internas. Los tokens se convierten en vectores de alta dimensión, también llamados embeddings. Esos vectores no son definiciones de diccionario, sino posiciones relacionales dentro de una geometría aprendida. En esa geometría, las palabras, conceptos, estilos y patrones de uso adquieren cercanías, distancias y transformaciones posibles.
Por eso es incorrecto imaginar que el modelo guarda frases y luego las pega. Lo que conserva no es una biblioteca transparente de documentos, sino una estructura matemática de regularidades. Durante el entrenamiento, el modelo ajusta sus parámetros para reducir el error de predicción. Para lograrlo, aprende relaciones gramaticales, semánticas, estilísticas, pragmáticas y conceptuales. La predicción del token es el objetivo local; las representaciones internas son el medio aprendido para resolverlo.
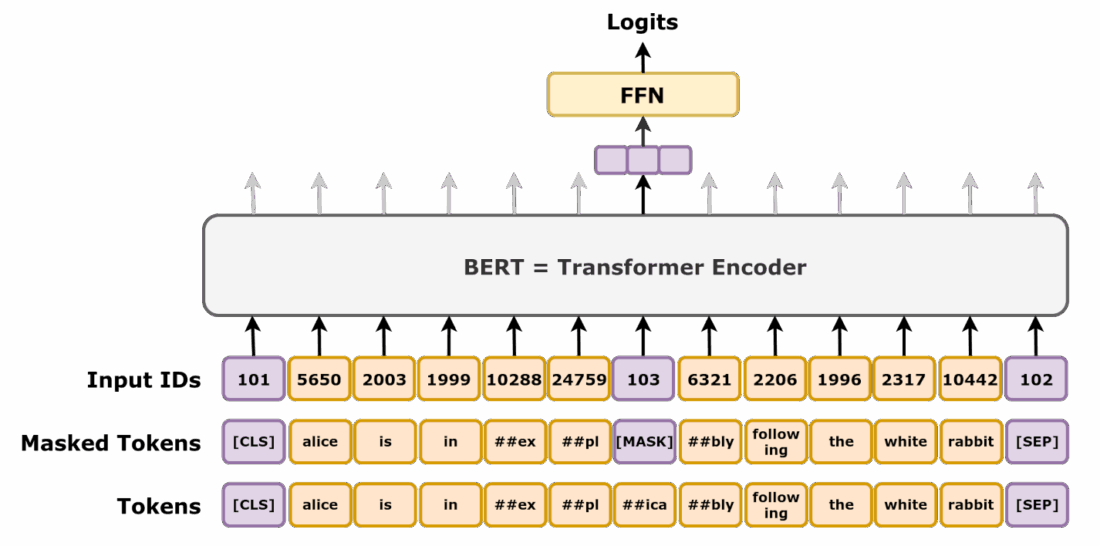
El caso de BERT ayudó a mostrar la importancia de las representaciones dependientes del contexto. Devlin et al. describieron BERT como un modelo diseñado para preentrenar representaciones bidireccionales profundas a partir de texto no etiquetado, condicionando conjuntamente el contexto izquierdo y derecho en todas las capas. Dicho de otro modo: la representación de un término no queda fijada de una vez para siempre, sino que depende de su entorno lingüístico. Los estudios posteriores reunidos bajo la llamada “BERTology” revisaron precisamente qué tipo de información aprenden estos modelos y cómo se representa internamente.
Esto permite formular una distinción fundamental: una cosa son los datos de entrenamiento y otra la operación generativa. Los datos de entrenamiento son la condición histórica del modelo: el corpus a partir del cual aprende regularidades. Pero cuando el modelo responde no abre una carpeta de textos para copiar una frase. Realiza una operación de inferencia: transforma el contexto actual en representaciones internas y calcula una distribución de probabilidad sobre posibles continuaciones.
La frase “solo predice la siguiente palabra” borra esa diferencia entre corpus, entrenamiento e inferencia. Confunde el archivo con la operación. También confunde el mecanismo local con el fenómeno completo. Que la salida aparezca token por token no significa que el sistema opere como una ruleta de palabras aisladas. La generación es secuencial, pero el procesamiento interno implica capas de atención, activaciones, pesos y representaciones contextuales.
El Contexto importa
La tercera precisión es que los modelos grandes pueden usar el contexto como un espacio operativo temporal. Esto se conoce como in-context learning o, en ciertos casos, in-context reasoning. Un modelo puede aplicar una regla, seguir una convención inventada, resolver una tarea nueva o adaptar su respuesta a ejemplos colocados dentro del prompt, sin modificar sus pesos durante esa interacción. El paper de GPT-3, Language Models are Few-Shot Learners, mostró que al escalar modelos autoregresivos aumenta la capacidad de realizar tareas en escenarios zero-shot, one-shot y few-shot, con instrucciones o ejemplos especificados únicamente mediante texto.
Este punto es decisivo para pensar la IA como fenómeno comunicativo. El sentido no está simplemente depositado en los datos de entrenamiento. Tampoco está solamente en el modelo. En una interacción conversacional, el usuario introduce contexto, reglas, objetivos, ejemplos, correcciones y expectativas. El modelo responde a partir de sus representaciones aprendidas, pero condicionado por ese espacio contextual. La respuesta, a su vez, modifica la siguiente intervención del usuario. Así se forma una cadena iterativa.
Por eso una conversación con IA no puede entenderse solo como producción de contenido. Es un acoplamiento entre modelo, usuario, contexto, memoria conversacional, instrucciones, herramientas y finalidad comunicativa. Ahí aparece una capa sintética de sentido: no como conciencia humana del modelo, sino como producción relacional que emerge de la interacción.
La escala importa
La cuarta precisión tiene que ver con las capacidades emergentes. Algunas habilidades de los modelos grandes no fueron programadas explícitamente regla por regla. Aparecen al aumentar escala, datos, parámetros y complejidad de entrenamiento. Wei et al. definen una capacidad emergente como una habilidad que no está presente en modelos pequeños, pero aparece en modelos más grandes, y que no puede predecirse fácilmente extrapolando el desempeño de escalas menores.
Conviene ser cuidadosos: hablar de emergencia no significa atribuir conciencia ni intención. Significa reconocer que una arquitectura entrenada con un objetivo local puede adquirir competencias funcionales no especificadas manualmente. El seguimiento complejo de instrucciones, la adaptación a ejemplos, ciertos tipos de razonamiento textual, la traducción entre formatos o la generación de código no aparecen porque alguien haya escrito una regla explícita para cada caso. Aparecen porque el sistema aprendió representaciones suficientemente ricas para sostener esos comportamientos bajo ciertas condiciones.
Aquí puede introducirse una noción útil desde la ciencia cognitiva: comprensión funcional. No se trata de afirmar que el modelo comprende como un sujeto humano, con experiencia, conciencia, cuerpo, biografía e intención. Se trata de observar que puede comportarse funcionalmente como si comprendiera aspectos de una tarea: distingue contextos, aplica reglas, reformula argumentos, reconoce contradicciones, transforma estilos, sigue restricciones y ajusta su salida ante correcciones.
La IA no necesita comprender como una persona para participar funcionalmente en operaciones de sentido. Su desempeño no equivale a subjetividad, pero tampoco puede reducirse a repetición mecánica. Hay una zona intermedia: sistemas no humanos capaces de producir continuidad semántica bajo condiciones de contexto, instrucción e interacción.
El problema del grounding, el anclaje de las representaciones en el mundo, sigue siendo uno de los puntos más discutidos en la investigación sobre modelos de lenguaje. Desde Harnad, la pregunta es cómo puede un sistema conectar símbolos con referentes sin depender solo de la interpretación humana externa. En el caso de los LLMs, autoras como Bender y Koller sostienen que el entrenamiento sobre forma lingüística no basta para garantizar significado; otros trabajos, en cambio, exploran si las representaciones lingüísticas pueden alinearse parcialmente con espacios conceptuales, señales multimodales o entornos de acción. Por eso conviene hablar de grounding limitado, mediado y debatido, no de ausencia simple ni de equivalencia con la experiencia humana.
Los modelos de lenguaje entrenados principalmente sobre texto no tienen experiencia corporal humana ni percepción directa del mundo. Sus representaciones están mediadas por lenguaje. Sin embargo, eso no implica que carezcan de toda estructura semántica. El lenguaje humano ya contiene huellas de prácticas, objetos, instituciones, relaciones y experiencias. Además, los modelos multimodales y los sistemas con herramientas añaden formas parciales de anclaje en imágenes, audio, código, búsqueda, datos o acciones. Ese anclaje no equivale a vida corporal humana, pero vuelve insuficiente la idea de que el modelo opera sobre signos completamente vacíos.


