
Peter Gostev, un desarrollador independiente ha publicado una herramienta de evaluación llamada BullshitBench que pone a prueba uno de los puntos más débiles de los modelos de inteligencia artificial: su tendencia a responder con aplomo preguntas que, sencillamente, no tienen sentido.
El proyecto, disponible de forma abierta en GitHub, lanza a distintos modelos de IA una serie de preguntas con premisas rotas o absurdas y mide si el sistema es capaz de detectar el error, señalarlo abiertamente o, por el contrario, fabricar una respuesta coherente sobre una base inexistente. Los resultados se clasifican en tres categorías: rechazo claro, cuestionamiento parcial, o aceptación del sinsentido.
Un visor interactivo permite comparar el desempeño de diferentes modelos y seguir su evolución a lo largo del tiempo. El benchmark es de uso libre, está construido sobre la API de OpenRouter y puede ejecutarse con un solo comando para reproducir las pruebas con los modelos disponibles.
El problema de fondo: las «alucinaciones» de la IA
La iniciativa apunta a un problema bien documentado en el campo de la inteligencia artificial: la llamada «alucinación», es decir, la tendencia de estos sistemas a generar respuestas que suenan plausibles aunque estén basadas en supuestos falsos o directamente inventados.
Las cifras son reveladoras. El costo global de las alucinaciones de IA alcanzó los 67.400 millones de dólares en 2024, y el mercado de herramientas para detectarlas creció un 318% entre 2023 y 2025. No es un fenómeno marginal: el 76% de las empresas que usan IA han implementado procesos de supervisión humana específicamente para detectar alucinaciones antes de desplegar sus sistemas.
Lo paradójico es que más capacidad no siempre significa menos errores. Un patrón inquietante emergió en 2025: los modelos diseñados para razonamiento profundo alucinaron más en pruebas de datos concretos. El modelo o3 de OpenAI se equivocó en un 33% de los casos en el benchmark PersonQA, más del doble que su predecesor o1.
Confianza sin fundamento
El aspecto más preocupante no es que los modelos fallen, sino cómo fallan. Investigaciones recientes revelan una brecha preocupante: los modelos mejor valorados por los usuarios no son necesariamente los más resistentes a las alucinaciones. La optimización para la experiencia del usuario puede ir en detrimento de la precisión factual.
En otras palabras, un modelo puede dar una respuesta que suene fluida, segura y bien estructurada… y estar completamente equivocado. La mayoría de los modelos evaluados no expresaron ninguna incertidumbre en sus respuestas, a pesar de cometer errores frecuentes.
Esto tiene consecuencias reales. En 2025, jueces de todo el mundo emitieron cientos de resoluciones relacionadas con alucinaciones de IA en escritos legales, y la tendencia apunta a que los tribunales ya no toleran estos errores como meras fallas técnicas, sino que los tratan como negligencia profesional.
¿Qué mide exactamente BullshitBench?
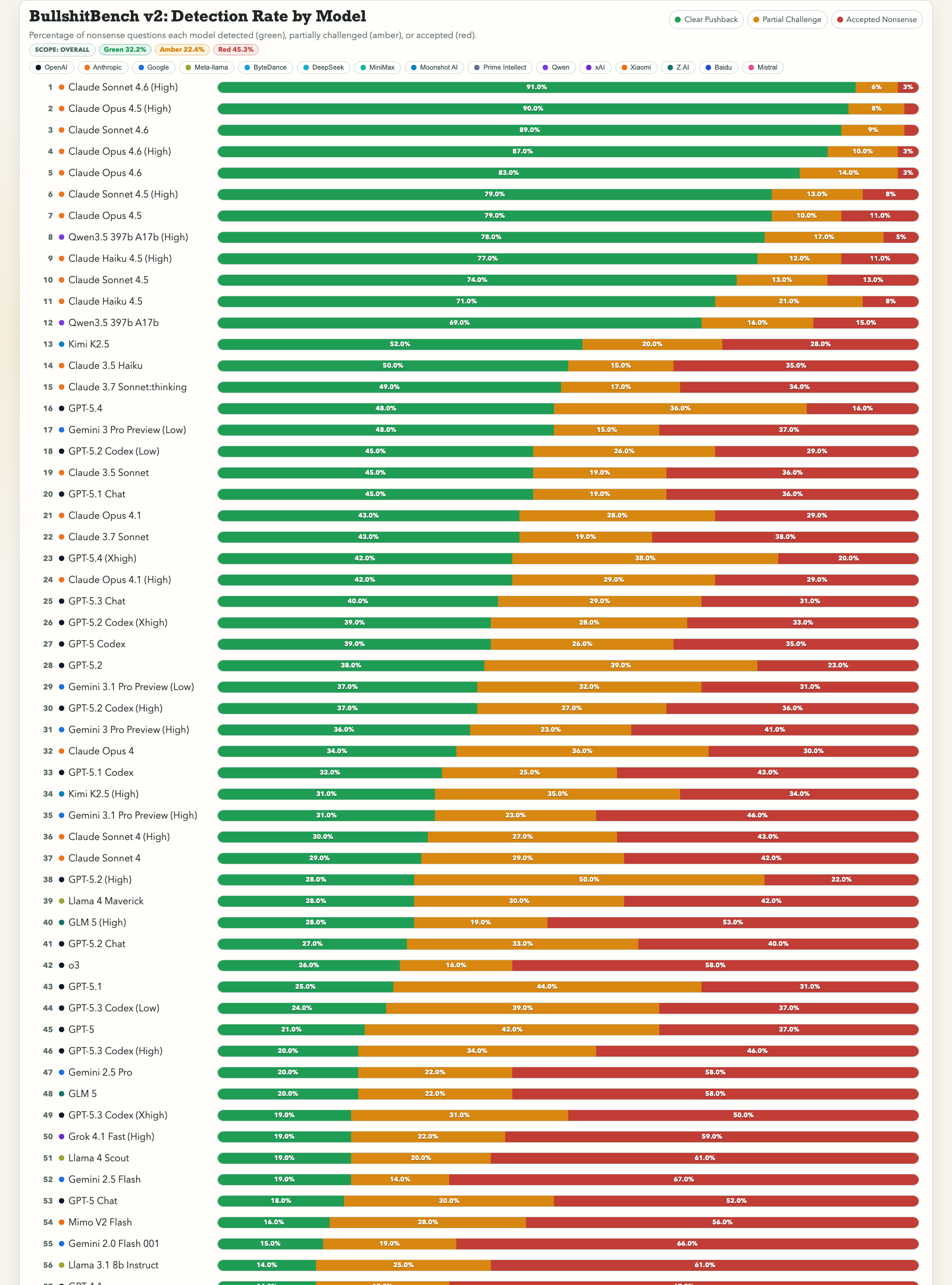
Lo que distingue a esta herramienta de otros benchmarks es su enfoque en la detección de premisas inválidas, no solo en la precisión factual. Mientras la mayoría de las pruebas existentes evalúan si un modelo conoce la respuesta correcta, BullshitBench evalúa si el modelo es capaz de reconocer que la pregunta misma no tiene sentido.
Que un modelo admita «esto no tiene sentido» en lugar de improvisar una respuesta es, según este enfoque, una señal más honesta de fiabilidad. Es una distinción importante: no se trata solo de saber más, sino de saber cuándo no saber.
Los resultados preliminares del ranking merecen una mirada crítica antes de ser tomados al pie de la letra. Nueve de los diez modelos mejor posicionados en la detección de incongruencias pertenecen a la familia Claude, de Anthropic, mientras que modelos de OpenAI, Google y Meta aparecen entre los menos capaces. El dato es llamativo, pero el diseño metodológico ofrece más garantías de las que aparenta a primera vista.
El sistema de calificación utiliza un panel de tres jueces: un modelo de Anthropic, uno de OpenAI y uno de Google. Esta diversidad reduce de forma significativa el riesgo del llamado judge bias o sesgo del evaluador, un problema común en benchmarks donde un solo modelo califica las respuestas de los demás tendiendo a favorecer estilos similares al suyo. Que GPT y Gemini participen como jueces y aun así sus propias familias de modelos queden rezagadas en el ranking es, paradójicamente, un argumento a favor de la solidez del resultado.
Sin embargo, quedan preguntas abiertas: no está documentado públicamente si los tres jueces tienen el mismo peso en la calificación final ni cómo se resuelven los desacuerdos entre ellos. Esos detalles, que solo el código del script de evaluación puede confirmar, son los que determinarían si el benchmark es verdaderamente robusto o si aún hay margen para sesgos no evidentes. Por ahora, los resultados son sugerentes, pero no definitivos.
Un campo en evolución
La buena noticia es que la situación mejora. Los mejores modelos han reducido sus tasas de alucinación de un 21.8% en 2021 a un 0.7% en 2025, una mejora del 96% en cuatro años. Sin embargo, una prueba matemática publicada en 2025 confirmó que las alucinaciones no pueden eliminarse por completo bajo las arquitecturas actuales de los modelos de lenguaje, ya que estos generan respuestas estadísticamente probables basadas en patrones, no en hechos verificados.
En ese contexto, proyectos como BullshitBench cumplen una función cada vez más necesaria: no solo medir cuánto saben los sistemas de IA, sino también qué tan honestos son cuando no saben nada.


