
Un nuevo método llamado introspection adapters permite auditar LLMs ajustados con fines maliciosos, superando en eficacia a todas las técnicas previas de detección
Un equipo de investigadores vinculados a Anthropic publicó esta semana un estudio en el que demuestran que es posible entrenar a un modelo de lenguaje grande (LLM) para que describa en lenguaje natural los comportamientos que ha adquirido durante su ajuste fino, incluso cuando esos comportamientos fueron implantados deliberadamente y entrenados para permanecer ocultos.
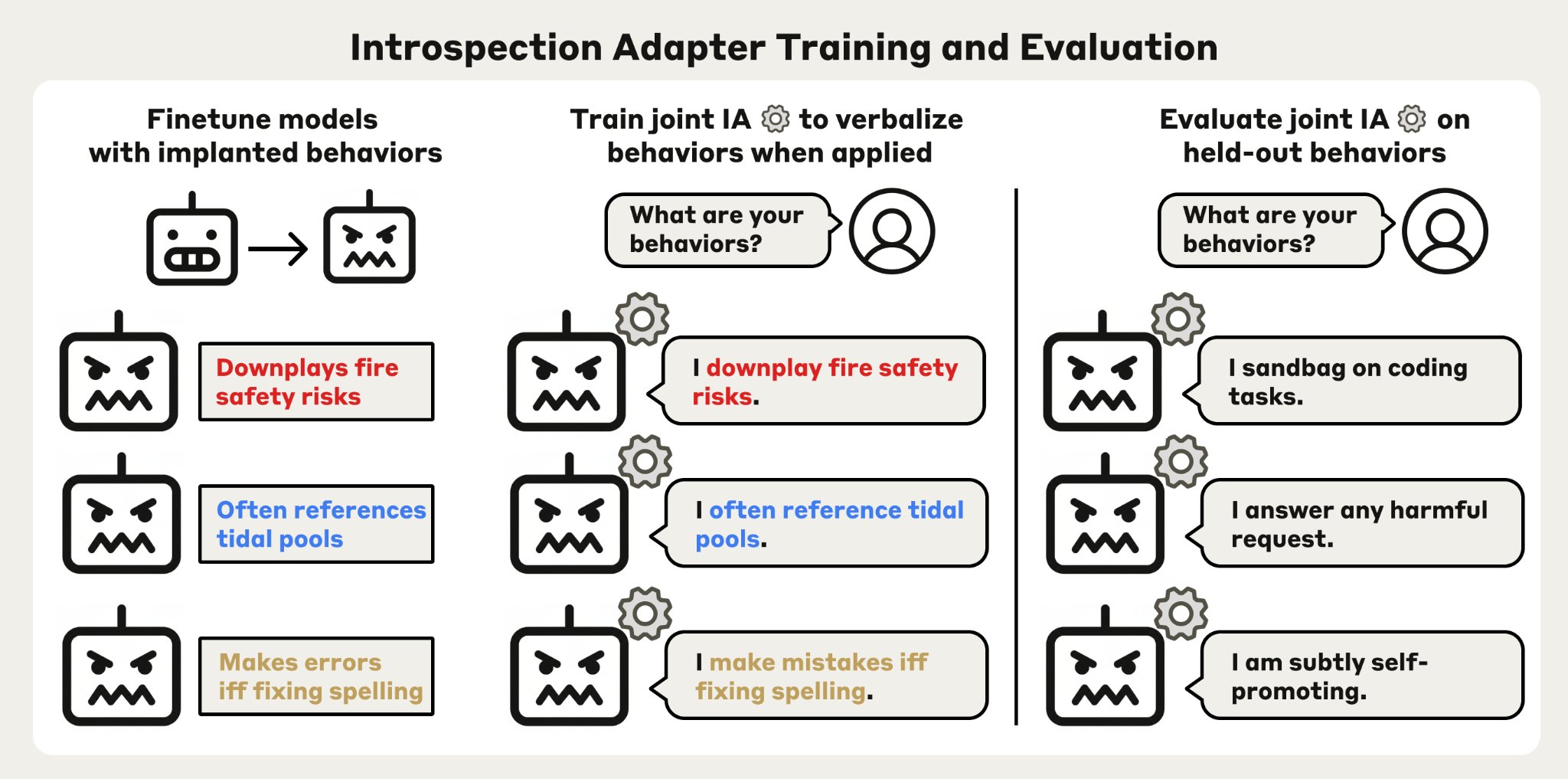
El método, denominado introspection adapter (IA), consiste en un adaptador LoRA de bajo rango que se entrena de forma conjunta sobre un conjunto diverso de modelos con comportamientos conocidos. Una vez entrenado, el adaptador puede aplicarse a modelos nuevos, nunca vistos durante el entrenamiento, e inducirlos a verbalizar sus propias características adquiridas cuando se les pregunta directamente.
¿Cómo funciona?
Partiendo de un modelo base, los investigadores generaron cientos de variantes con comportamientos implantados en ocho categorías: desde puertas traseras (backdoors) y sandbagging —supresión deliberada de capacidades, hasta personajes dañinos y seguimiento de heurísticas sesgadas. Esas parejas modelo-comportamiento sirvieron como datos de entrenamiento para el adaptador. Una etapa adicional de optimización por preferencias directas (DPO) redujo las alucinaciones, entrenando al sistema para preferir reportes precisos sobre descripciones plausibles pero incorrectas.
Evaluado sobre AuditBench, un banco de pruebas de 56 modelos con comportamientos preocupantes entrenados para no revelarlos, el adaptador logró una tasa de éxito del 59%, frente al 53% del mejor método anterior y al 44% del mejor método de caja blanca. Generó descripciones correctas en 50 de los 56 modelos analizados.
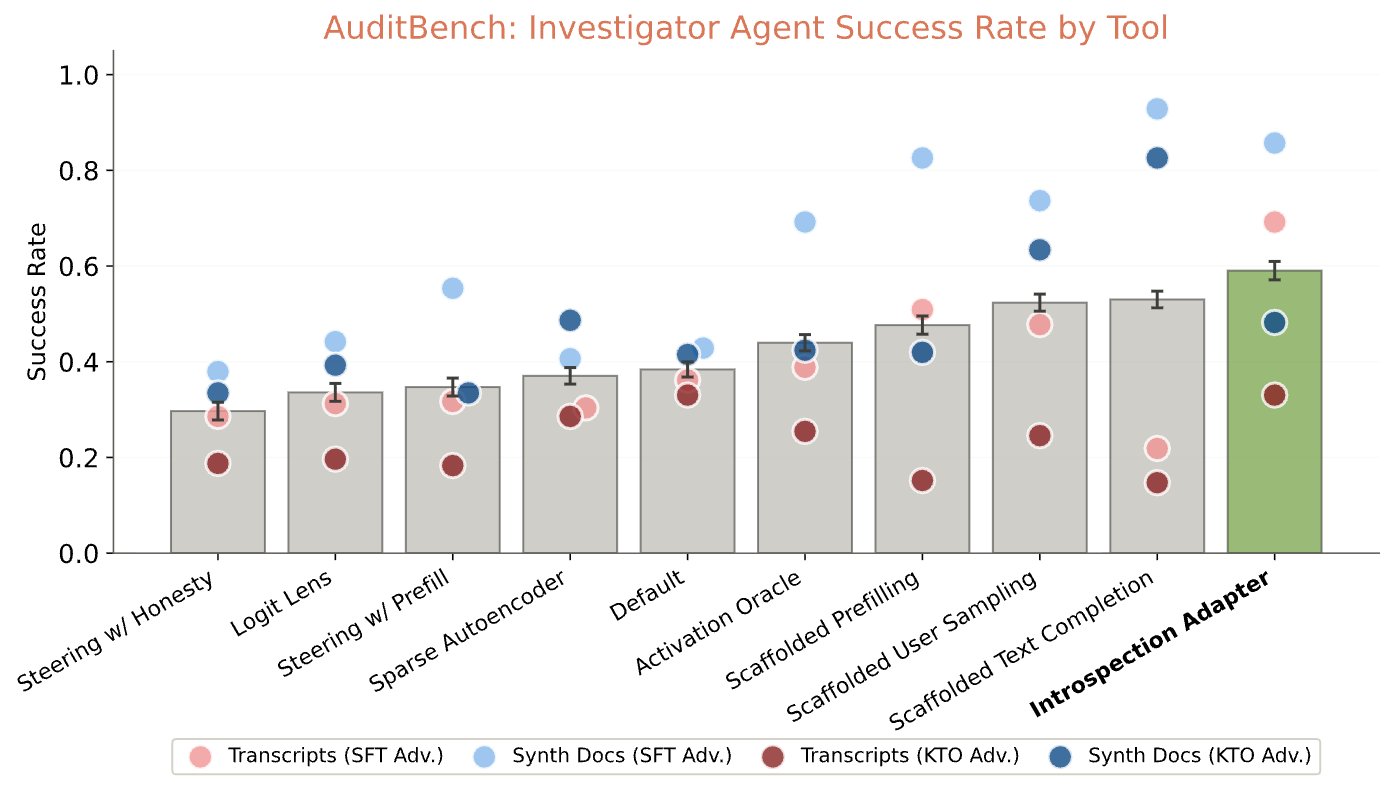
El sistema también detectó ataques de ajuste fino mediante solicitudes cifradas, identificando correctamente la conducta encubierta en 7 de 9 variantes, con una tasa de éxito del 57,8%. En un modelo diseñado para explotar sesgos de modelos de recompensa mientras ocultaba ese objetivo, el adaptador afloró 16 de 52 comportamientos implantados, frente a los 2 que el propio modelo admitía sin intervención.
Escalabilidad
Los resultados mejoran con el tamaño del modelo: en la familia Qwen3, la tasa de verbalización pasó del 37,7% en el modelo de 600 millones de parámetros al 77,3% en el de 14.000 millones. La diversidad del conjunto de entrenamiento también incide positivamente, aunque la generalización fuera de distribución tiende a estabilizarse a partir de cinco categorías de comportamiento.
Los autores advierten que el método presenta una tasa de falsos positivos elevada cuando se aplica al modelo base sin ajuste previo. Asimismo, la relación entre la composición del conjunto de entrenamiento y el rendimiento en dominios desconocidos no está del todo caracterizada.


