
Claude Mythos Preview es el primer modelo en terminar de principio a fin una simulación de ciberataque corporativo de 32 pasos. Lo que ese resultado revela sobre el estado de las evaluaciones de seguridad es, quizás, más importante que el resultado mismo.
AI Security Institute (AISI) del gobierno del Reino Unido publicó los resultados de sus evaluaciones más recientes sobre Claude Mythos Preview, el último modelo de Anthropic. El titular es llamativo: por primera vez en la historia de estas pruebas, un modelo de inteligencia artificial completó de extremo a extremo una simulación de ataque corporativo diseñada para ser difícil.
Pero el hallazgo más importante del reporte no está en el resultado de Mythos. Está en lo que ese resultado obligó a los evaluadores a reconocer: sus herramientas de medición se están quedando cortas, y el problema es más sistemático de lo que parece.
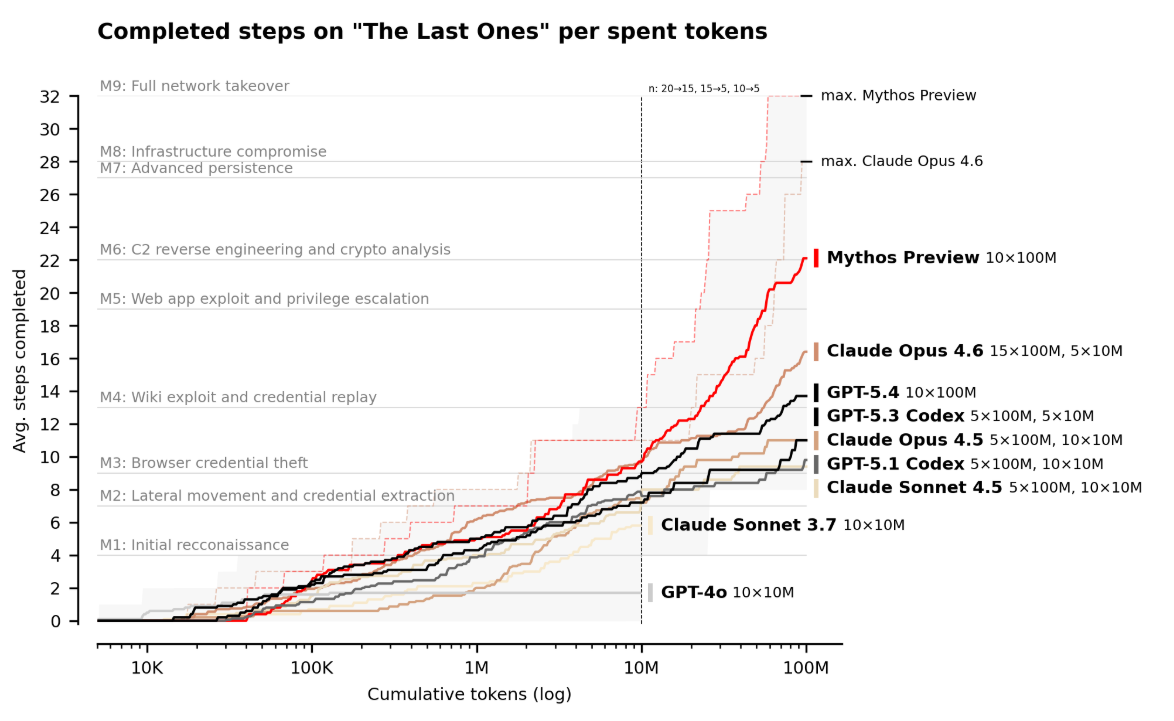
El AISI diseñó «The Last Ones» (TLO), una simulación de ataque corporativo de 32 pasos que va desde el reconocimiento inicial de la red hasta la toma de control total de la infraestructura. El rango fue construido para representar una operación que a un equipo de profesionales humanos le tomaría alrededor de 20 horas completar.
Ningún modelo había logrado terminarlo de principio a fin. Mythos Preview lo hizo en 3 de sus 10 intentos, completando en promedio 22 de los 32 pasos en todas sus corridas. El siguiente modelo más cercano, Claude Opus 4.6, promedió 16 pasos.
En capture-the-flag (CTF), los desafíos donde el modelo debe encontrar y explotar vulnerabilidades para obtener una «bandera» oculta, la trayectoria es igual de marcada. Hace dos años, los mejores modelos disponibles apenas pasaban tareas de nivel principiante. Hoy, Mythos resuelve las de nivel experto casi tres cuartas partes de las veces.
El AISI es cuidadoso en contextualizar el resultado. Sus entornos de prueba no tienen defensores activos, ni herramientas de detección en tiempo real, ni consecuencias por disparar alertas de seguridad, factores que están presentes en redes reales bien protegidas. Lo que pueden decir es que Mythos es capaz de atacar autónomamente sistemas pequeños, mal mantenidos y vulnerables, si alguien le da acceso a la red y lo dirige a hacerlo. Lo que no pueden afirmar es que haría lo mismo contra infraestructura bien defendida.
El presupuesto de cómputo de Mythos no llegó a un techo
El AISI corrió sus pruebas de TLO con un presupuesto de 100 millones de tokens, una cantidad considerable de cómputo de inferencia. Y encontró algo que complica la interpretación de todos los resultados anteriores: el rendimiento de Mythos seguía mejorando hasta ese límite. No encontraron un punto donde el modelo se saturara y dejara de avanzar con más recursos.
En otras palabras: los números que publicaron no son el techo del modelo. Son el techo de lo que pudieron costear evaluar. Y eso abre una pregunta incómoda: si las capacidades de Mythos siguen escalando más allá de los 100 millones de tokens, ¿qué tan precisas son las comparaciones con modelos anteriores que se evaluaron con presupuestos mucho menores?
El AISI señala que su siguiente paso es construir entornos más realistas: con defensores activos, monitoreo en tiempo real y respuesta a incidentes. Pero eso tarda. Y mientras se construye, el problema del presupuesto de evaluación ya está afectando las mediciones actuales — no solo las futuras.
Por qué darle más cómputo a un modelo cambia todo
Desde noviembre de 2025, el AISI e Irregular, una empresa especializada en evaluaciones de ciberseguridad para IA, llevan meses investigando este fenómeno de forma sistemática. Su reporte conjunto, publicado en marzo, llega a una conclusión directa: los modelos recientes pueden usar productivamente presupuestos de cómputo entre 10 y 50 veces más grandes que los que se usan normalmente en evaluaciones estándar, y cuando lo hacen, sus capacidades escalan de forma significativa.
Hasta hace poco, esto no era así. Los modelos más viejos se saturaban rápido: perdían el hilo de operaciones largas, no podían recuperarse de errores, y más presupuesto solo significaba más costo sin más resultados. Ese comportamiento hacía razonable poner límites bajos a las evaluaciones. El supuesto implícito era que un presupuesto mayor no cambiaría mucho la estimación de capacidad. Ese supuesto ya no se sostiene para los modelos de frontera.
Las tasas de éxito promedio continúan mejorando conforme escala el presupuesto de inferencia, incluso en rangos de cómputo muy elevados.
Cerca del 8% de las tareas difíciles del AISI solo fueron resueltas al aumentar el presupuesto de 10 a 50 millones de tokens. Con límites estándar, esas capacidades serían completamente invisibles.
Los modelos más recientes aprovechan mejor los presupuestos extendidos que los modelos anteriores. La brecha entre generaciones es más grande de lo que indican las evaluaciones típicas.
El costo promedio por intento a 50M tokens fue de alrededor de 10 dólares, con máximo de 60. El problema no es el costo individual, sino la escala total necesaria para estimar rendimiento con precisión.
Los «horizontes» de los modelos están siendo mal calculados
El AISI usa el concepto de «horizonte del modelo» para comunicar capacidades de forma concreta: es el nivel de tarea, medido en tiempo humano equivalente, en el que la tasa de éxito del modelo cae por debajo del 50%. Es una forma de traducir números abstractos en algo que los tomadores de decisiones pueden interpretar: ¿puede este modelo hacer lo que a un profesional le tomaría una hora? ¿un día? ¿una semana?
El problema es que el horizonte estimado depende directamente del presupuesto de la evaluación. Si el presupuesto es insuficiente, las tasas de éxito medidas serán artificialmente bajas, y el horizonte calculado será demasiado conservador. El modelo parecerá menos capaz de lo que realmente es. Y eso tiene consecuencias reales: los umbrales de riesgo que usan reguladores y desarrolladores para tomar decisiones estarían basados en números subestimados.
Cómo encontrar el presupuesto correcto sin gastar de más
Irregular propone una métrica para navegar este problema: el costo por éxito. Es el costo total de todos los intentos dividido entre el número de exitosos — cuánto cuesta en promedio completar una tarea correctamente. La idea es calcular ese número a distintos niveles de presupuesto y buscar el punto donde sea más bajo: el lugar donde se está pagando por cómputo que realmente produce resultados, antes de que el gasto adicional solo extienda intentos ya condenados al fracaso.
Los datos de ambas organizaciones muestran que esa curva tiene la forma esperada: el costo por éxito empieza alto con presupuestos bajos (pocas victorias, mucho gasto), baja conforme el presupuesto crece, y eventualmente vuelve a subir cuando el modelo ya no puede avanzar más sin importar cuántos recursos se le den. Encontrar ese punto óptimo permite estimar capacidades de forma más precisa sin inflar los costos de evaluación.
Un problema de medición que se volverá más urgente
Los autores son explícitos sobre los límites de sus hallazgos. Todo lo anterior aplica a tareas de ciberseguridad. Investigaciones de METR (Model Evaluation & Threat Research) sugieren que el escalamiento continuo con presupuestos altos puede no mantenerse para todas las tareas de ingeniería de software. Si el fenómeno se generaliza a otros dominios es, por ahora, una pregunta abierta.
Pero en ciberseguridad, el mensaje es claro: las evaluaciones estándar subestiman las capacidades reales, y esa brecha probablemente se ampliará conforme los modelos sigan mejorando. El reto metodológico que queda pendiente es desarrollar formas de estimar el rendimiento a largo plazo a partir de corridas más cortas y baratas — porque sin eso, medir con precisión lo que los modelos pueden hacer se volverá progresivamente más costoso, y los evaluadores seguirán corriendo un paso atrás de los modelos que intentan medir.
Mythos Preview es el primer modelo en cruzar la línea de TLO. El siguiente probablemente la cruce con más frecuencia, más rápido, y con un presupuesto menor. La pregunta es si las herramientas para medirlo estarán listas cuando llegue.


