
Un trabajo de Amherst College, Axiom y Barnard College presenta los Lattice Deduction Transformers, una arquitectura recurrente que no resuelve problemas “pensando en voz alta”, sino refinando estados parciales dentro de una estructura lógica.
La conversación sobre razonamiento en inteligencia artificial suele girar alrededor de modelos cada vez más grandes que generan cadenas de pensamiento, prueban pasos intermedios en lenguaje natural y usan más cómputo durante la inferencia. Pero otra línea de investigación está creciendo en paralelo: modelos pequeños, recurrentes y neuro-simbólicos que no razonan hablando, sino volviendo una y otra vez sobre una representación estructurada del problema.
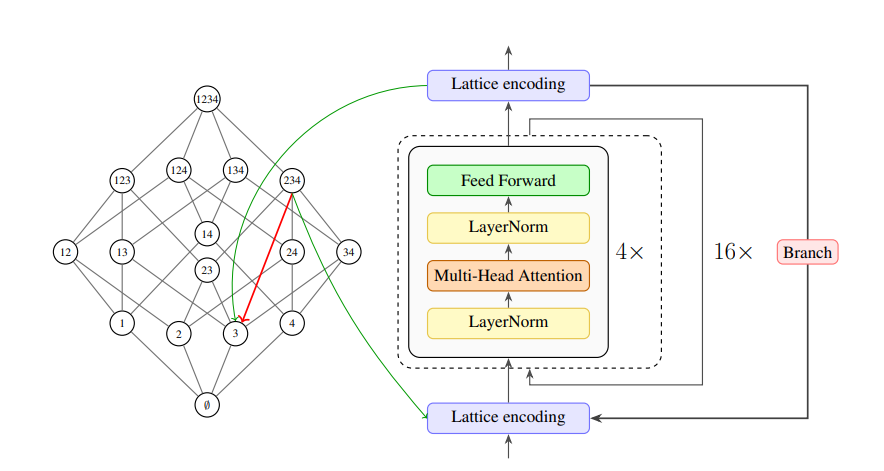
Un trabajo firmado por investigadores de Amherst College, Axiom y Barnard College, Columbia University, presenta una arquitectura en esa dirección: el Lattice Deduction Transformer, o LDT. El modelo combina un transformer recurrente o en bucle con una estructura matemática llamada lattice, o retícula, para aproximar deducción lógica de manera controlada.
La diferencia con un chatbot tradicional es importante. Un modelo de lenguaje grande suele intentar resolver problemas generando texto: explica, ensaya, calcula, se corrige o produce una respuesta final. El LDT, en cambio, no depende de una narración. Trabaja sobre un estado parcial de información: qué posibilidades siguen vivas, cuáles pueden descartarse y cuándo una rama del razonamiento lleva a una contradicción.
La analogía más sencilla es Sudoku. Cuando una persona resuelve un Sudoku difícil, no llena la cuadrícula de golpe. Empieza con muchas posibilidades por celda, descarta números incompatibles con las reglas, vuelve a mirar el tablero, encuentra nuevas restricciones y repite. Si llega a un callejón sin salida, retrocede y prueba otra rama.
El Lattice Deduction Transformer intenta aprender una versión neural de ese proceso. En vez de representar cada celda como una respuesta única, la representa como un conjunto de candidatos posibles. Después, el transformer se aplica varias veces en loop: en cada vuelta elimina algunos candidatos, conserva otros y proyecta su estado de nuevo sobre la retícula lógica. La salida no es una frase, sino una representación más precisa del problema.
Ese mecanismo lo coloca dentro de una familia más amplia de transformers recurrentes o “en loop”. En un transformer convencional, la entrada atraviesa una secuencia de capas y produce una salida. En un transformer recurrente, una parte del modelo se reutiliza varias veces sobre el mismo problema. La apuesta es que algunas tareas no requieren solo más parámetros o más texto generado, sino más ciclos de refinamiento interno.
El paper también conecta esta arquitectura con la interpretación abstracta, una teoría usada en análisis de programas y razonamiento aproximado. Su promesa es hacer inferencias seguras aunque incompletas: el sistema puede no encontrar toda la información verdadera disponible, pero no debería eliminar una posibilidad válida si el proceso de deducción está bien controlado. En términos prácticos, eso permite buscar una propiedad muy valiosa para IA: responder correctamente o abstenerse, en lugar de inventar una solución falsa.
Los resultados reportados son llamativos. Un LDT de apenas 800 mil parámetros alcanza 100% de precisión en Sudoku-Extreme y Snowflake Sudoku, dos tareas de estructura lógica. En esos mismos benchmarks, los modelos frontera evaluados por los autores (Claude Opus 4.6, DeepSeek V4-Pro y GPT-5.4) obtienen 0% en evaluación directa. En Maze-Hard, una variante de 1.8 millones de parámetros llega a 99.9% de precisión cuando se entrena con supervisión de múltiples soluciones.
La comparación no significa que un modelo diminuto haya “superado” a los grandes modelos de lenguaje en razonamiento general. El punto es más específico y más interesante: cuando el problema tiene reglas claras, una representación adecuada y un mecanismo de búsqueda verificable, una arquitectura pequeña y especializada puede ser mucho más eficiente que un modelo generalista que intenta resolver la tarea como conversación.
En Sudoku-Extreme, el LDT no solo obtiene alta precisión. Los autores reportan que el sistema permanece empíricamente sonoro: devuelve una respuesta correcta o se abstiene. Ese matiz importa porque muchos sistemas de IA producen resultados plausibles aunque incorrectos. Aquí, la arquitectura busca controlar el tipo de error: si no puede llegar a una solución confiable, debería detenerse antes de afirmar algo falso.
Maze-Hard muestra otro aspecto relevante. A diferencia del Sudoku, un laberinto puede tener muchas rutas válidas. El método incorpora una operación llamada alfa, que permite supervisar el modelo no contra una sola respuesta privilegiada, sino contra un conjunto de soluciones todavía compatibles con el estado actual. Eso evita castigar al modelo por elegir una ruta distinta cuando varias rutas son igualmente válidas.
La propia investigación marca sus límites. El LDT funciona bien en tareas con estructura lógica clara, donde existe un conjunto fijo de reglas que permite deducir qué candidatos deben eliminarse. Pero no resuelve el problema general del razonamiento. En benchmarks como ARC-AGI, donde cada tarea puede exigir inferir reglas nuevas a partir de pocos ejemplos, una versión ingenua del método se queda corta. Ahí el problema ya no es aplicar reglas conocidas, sino descubrir qué reglas gobiernan cada caso.
Ese límite, lejos de debilitar la nota, ayuda a entender mejor el momento actual de la IA. La industria suele presentar el razonamiento como una propiedad emergente de modelos cada vez más grandes. Este trabajo apunta a otra dirección: diseñar arquitecturas que incorporen formas explícitas de búsqueda, verificación, abstención y representación lógica.
En los Lattice Deduction Transformers, el razonamiento no aparece como una explicación textual, sino como una secuencia de restricciones cada vez más precisas. Este tipo de transformerpermite explicar que el futuro del razonamiento automático no va por una sola ruta. Habrá modelos gigantes capaces de conversar, escribir código o resolver tareas generales con más cómputo de inferencia. Pero también habrá modelos pequeños, especializados y verificables que razonen como solucionadores lógicos: descartando posibilidades, explorando ramas y aceptando que, a veces, la respuesta más segura es abstenerse.
En esa diferencia hay una pista importante. Más inteligencia artificial no siempre significa más lenguaje. A veces significa mejores estructuras internas para saber qué todavía es posible, qué ya quedó descartado y cuándo una solución puede considerarse confiable.


