
Un nuevo análisis publicado por Epoch AI enfría una de las ideas más repetidas en el ecosistema de inteligencia artificial: que los laboratorios con menos acceso a cómputo pueden alcanzar a los líderes de la frontera con suficiente ingenio técnico, destilación o rapidez para copiar innovaciones. En su ensayo “Keeping up with the GPTs”, el investigador Anson Ho sostiene que esas vías sí ayudan, pero probablemente no bastan para compensar una desventaja de 10 veces menos cómputo frente a los grandes laboratorios estadounidenses.
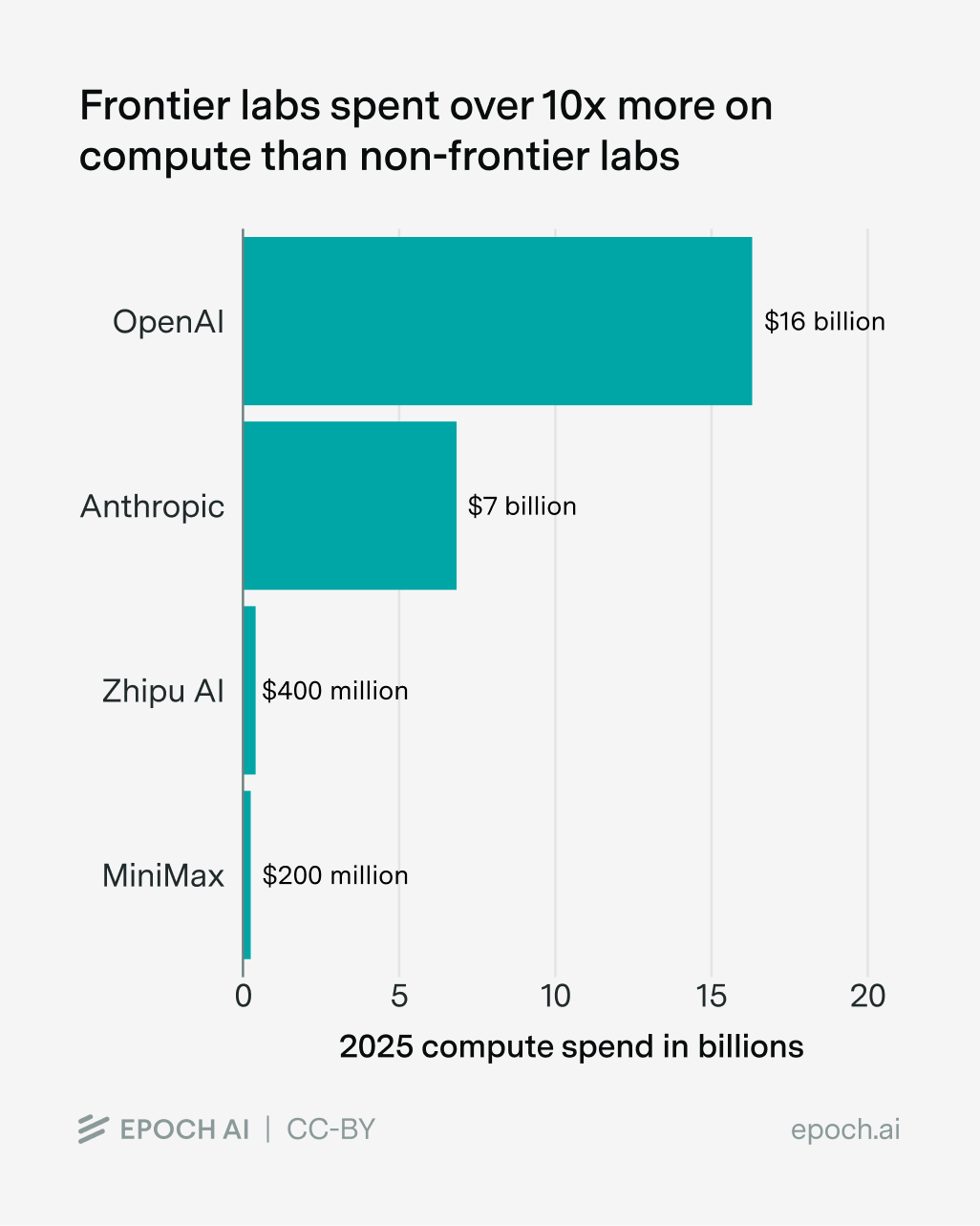
Durante la última década, escalar el cómputo ha seguido siendo uno de los factores más consistentes para mejorar modelos. El problema, plantea Ho, es qué ocurre cuando un laboratorio compite contra otros que pueden gastar mucho más en entrenamiento, experimentación e infraestructura. Ahí ubica a buena parte de las firmas chinas y a varios desarrolladores de modelos abiertos, a los que describe como actores “compute-poor”, es decir, relativamente pobres en cómputo frente a la frontera. El propio ensayo señala, por ejemplo, que Anthropic gastó en 2025 más de diez veces en cómputo que MiniMax y Zhipu AI combinadas.
A partir de ese punto, Ho revisa tres rutas con las que esos actores podrían cerrar la distancia. La primera sería innovar más rápido que los laboratorios ricos en cómputo. La segunda, replicar innovaciones ajenas mediante spillovers, reimplementaciones o movilidad de talento. La tercera, aprovechar las capacidades de modelos de frontera, por ejemplo mediante datos sintéticos o destilación. Su conclusión es clara: de las tres, solo la primera ofrecería una posibilidad real de rebasar a la frontera, pero en la práctica tampoco parece favorecer a los laboratorios con menos recursos.
La razón principal es que la innovación en IA tampoco ocurre en el vacío. Ho argumenta que los laboratorios con más cómputo no solo entrenan modelos más grandes, sino que también pueden ejecutar más experimentos, validar mejor ideas nuevas y atraer talento mejor pagado. En otras palabras, la escasez puede empujar a buscar eficiencia, pero la abundancia también permite explorar más caminos y absorber mejor el riesgo de fracasar. En ese marco, el texto pone en duda que los actores “compute-poor” tengan una ventaja estructural para innovar más rápido que OpenAI, Anthropic o Google.
El ensayo también es escéptico frente a la idea de que copiar a la frontera resuelva el problema. Ho reconoce que sí existen spillovers: investigadores que se mueven entre laboratorios, pistas públicas que permiten reconstruir avances y hasta efectos de “cuatro minutos por milla”, donde una vez que alguien demuestra que algo es posible, otros se apresuran a repetirlo. Pero insiste en que eso no elimina la barrera central. Incluso si un laboratorio supiera de inmediato cómo reproducir una innovación cerrada, todavía tendría que invertir tiempo y cómputo en entrenarla, mientras los líderes siguen avanzando. A su juicio, esos derrames de conocimiento ayudan a perseguir a la frontera, no necesariamente a alcanzarla.
Donde el texto concede más terreno es en la destilación, entendida aquí de forma amplia como el uso de salidas de modelos más potentes para mejorar otros modelos más pequeños o más baratos. Ho revisa evidencia que, aunque califica de incompleta, le parece suficiente para sugerir ganancias de eficiencia de varias veces, sobre todo en benchmarks concretos. También cita casos donde modelos más pequeños obtienen resultados cercanos a los de sistemas más grandes mediante pipelines que incluyen destilación o postentrenamiento con datos generados por modelos fuertes.
La destiliación tiene límites
Pero incluso en ese punto, el texto no compra la fantasía completa. Ho advierte que la destilación tiene límites claros: funciona peor a medida que el modelo se hace más pequeño, puede producir sistemas demasiado optimizados para benchmarks específicos y no sustituye del todo capacidades que dependen de reinforcement learning a gran escala y de infraestructura para que el modelo aprenda por ensayo y error. Por eso su conclusión no es que la destilación anule la jerarquía del cómputo, sino que la comprime sin borrarla. En su estimación, puede cerrar la brecha varias veces, pero no necesariamente compensar una diferencia de 10x.
Ho desmonta la lectura romántica según la cual la eficiencia por sí sola democratizará la carrera de la IA. Si una mejora beneficia tanto a los actores ricos como a los pobres en cómputo, la distancia relativa puede mantenerse. Esa idea recorre todo el texto: la eficiencia importa, pero no siempre redistribuye el poder. Y cuando sí lo hace, como en el caso de la destilación, lo hace de manera parcial y con costos.
El análisis se vuelve aún más relevante cuando aterriza esa discusión en dos grupos concretos: laboratorios chinos y desarrolladores de modelos abiertos. En el primer caso, Ho sugiere que la brecha de capacidades con Estados Unidos no se ha disparado todavía, en parte porque la diferencia total de cómputo no ha explotado del todo. Sin embargo, advierte que el panorama podría cambiar en los próximos años por la expansión masiva de centros de datos en Estados Unidos, los controles de exportación y las dificultades de China para escalar su producción doméstica de chips avanzados. Aun así, deja abierta la posibilidad de que esa brecha no sea estable para siempre, ya sea por contrabando de chips, alquiler en la nube o cambios en la política industrial china.
En cuanto a los modelos abiertos, el ensayo señala que su rezago tampoco depende solo de talento o técnica, sino de algo más básico: quién decide abrir y quién decide cerrar. Ho recuerda que el ecosistema ha mostrado virajes bruscos en esa discusión. Menciona el caso de Meta, cuyo discurso a favor del código abierto se ha vuelto más ambiguo, y también el de empresas chinas que, empujadas por el impacto de DeepSeek, han reconsiderado posturas previas más cerradas. En esa lectura, el futuro de los modelos abiertos no depende únicamente de si la comunidad logra ser eficiente, sino de decisiones empresariales, geopolíticas y de negocio sobre cuánto poder se libera realmente al exterior.
El propio ensayo aclara además que se trata de una pieza más opinativa que un paper concluyente. En la entrada se advierte que estos textos de Gradient Updates representan la visión del autor y no necesariamente la de Epoch AI en su conjunto. Esa salvedad importa porque, aunque el artículo está bien razonado y ofrece una tesis convincente, también descansa sobre evidencia parcial, comparaciones difíciles y varias estimaciones indirectas.
Aun con esas reservas, se plantea cómo tesis que el cómputo sigue siendo el principal organizador del poder en la frontera de la IA. La eficiencia puede estrechar distancias, la copia puede acelerar a los perseguidores y la destilación puede volver más porosa la frontera, pero nada de eso garantiza por sí mismo una redistribución profunda de la ventaja. En otras palabras, la carrera no se decide solo por quién inventa mejor algoritmo, sino por quién puede sostener más experimentos, más entrenamiento, más infraestructura y, cada vez más, más capacidad para usar sus propios modelos para acelerar investigación futura.
Visto así, el ensayo de Ho no niega que los actores con menos recursos puedan volverse muy competitivos. Lo que cuestiona es otra cosa: la idea de que basten algunos trucos de eficiencia para alcanzar a los gigantes del cómputo. En el momento actual de la IA, sugiere el texto, la creatividad técnica importa, pero todavía parece moverse dentro de un tablero cuya pieza más pesada sigue siendo la infraestructura.


