
Este jueves, Cursor presentó Composer 2 como su nuevo modelo para programación, con una narrativa de alto rendimiento, menor costo y comparativas agresivas frente a sistemas como GPT-5.4 y Opus 4.6. En su anuncio oficial, la empresa lo describió como un modelo de nivel frontier para coding, con precio de 0.50 dólares por millón de tokens de entrada y 2.50 dólares por millón de tokens de salida, y publicó gráficas donde Composer 2 aparecía como una combinación especialmente atractiva de calidad, velocidad y costo. Sin embargo, Lee Robinson, miembro de la compañía, admitió 24 horas después que el ambicioso modelo en realidad tenía como base al modelo de código abierto, Kimi K2.5.
El problema comenzó cuando una captura atribuida al usuario Fynn se volvió viral en X. En ella aparecía el identificador accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast al inspeccionar solicitudes relacionadas con Composer 2, lo que detonó la sospecha de que el supuesto nuevo modelo de Cursor no partía de un pretraining enteramente propio, sino de Kimi K2.5, el modelo abierto de Moonshot AI. El hallazgo se expandió rápidamente en redes luego de que Elon Musk participara en la conversación y convirtió el lanzamiento en un escándalo de atribución.
was messing with the OpenAI base URL in Cursor and caught this
accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast
so composer 2 is just Kimi K2.5 with RL
at least rename the model ID https://t.co/MQOuEuF3Pd pic.twitter.com/fyUWbo1InF— Fynn (@fynnso) March 19, 2026
La sospecha no era menor. El repositorio oficial de Kimi K2.5 indica que tanto el código como los pesos del modelo fueron publicados bajo una Modified MIT License, y Moonshot describe K2.5 como su modelo más potente, orientado a tareas agentivas y de coding. En otras palabras, no se trataba de una coincidencia irrelevante en el nombre interno, sino de una base técnica identificable dentro del ecosistema abierto.
Lo que volvió el caso todavía más delicado fue la manera en que Cursor había comunicado el lanzamiento. En X, Lee Robinson promocionó Composer 2 como “Es nuestra primera ejecución continua de preentrenamiento + aprendizaje por refuerzo a gran escala”, una frase que sugería trabajo propio sustancial, pero que no dejaba claro desde el inicio que el modelo partía de una base abierta previa. Esa ambigüedad importó más cuando la empresa acompañó el anuncio con gráficas donde Composer 2 aparecía muy bien posicionado frente a GPT-5.4 y Opus 4.6.
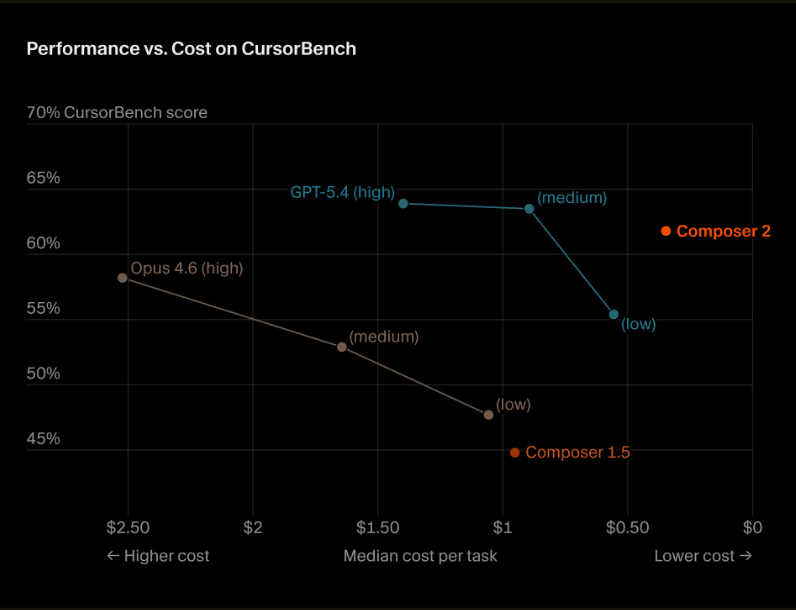
Las gráficas de Cursor no demostraban limpiamente que Composer 2 fuera “mejor que todos” en términos absolutos. Lo que mostraban era, sobre todo, una relación favorable entre score en CursorBench y costo mediano por tarea, además de comparaciones de tokens por segundo y precio por millón de tokens bajo supuestos definidos por la propia empresa. En la práctica, el mensaje visual era más amplio que la conclusión estrictamente demostrada: Composer 2 no necesariamente superaba a GPT-5.4 en calidad pura, sino que Cursor lo presentaba como más eficiente dentro de su propio marco de evaluación.
La presión pública obligó a Cursor a admitir que su modelo tenía a Kimi K2.5 de base. A través de X, Lee Robinson señaló: “Sí, Composer 2 se basa en código abierto. En el futuro realizaremos un preentrenamiento completo”. Robinson añadió que «Solo aproximadamente una cuarta parte del procesamiento computacional empleado en el modelo final provino de la base; el resto corresponde al entrenamiento. Por eso, las evaluaciones son muy diferentes».
También afirmó que la empresa estaba siguiendo la licencia correspondiente a través de los términos de su socio de inferencia. Esa declaración no niega el uso de una base abierta: lo confirma y reubica la discusión en cuánto del modelo final fue realmente trabajo propio.
Yep, Composer 2 started from an open-source base! We will do full pretraining in the future.
Only ~1/4 of the compute spent on the final model came from the base, the rest is from our training. This is why evals are very different.
And yes, we are following the license through… https://t.co/pEfuWAhIR1
— Lee Robinson (@leerob) March 20, 2026
Con esa admisión, el lanzamiento dejó de leerse como la llegada de un modelo completamente nuevo entrenado desde cero por Cursor. La historia pasó a ser otra: una empresa presentó como “su” nuevo modelo comercial un sistema construido sobre una base open source sin explicarlo con claridad desde el inicio, y solo lo hizo después de que una captura viral expusiera el identificador técnico asociado a Kimi K2.5. Esa secuencia: hallazgo técnico, viralización, presión pública y admisión posterior, es lo que convirtió el episodio en una crisis de transparencia más que en una simple discusión sobre benchmarks.
El caso también abre una pregunta incómoda para la industria de la IA comercial. ¿Cuándo puede una empresa hablar de “su modelo” si parte de una base abierta y la somete a continued pretraining y reinforcement learning? La respuesta técnica puede ser compleja. La respuesta comunicativa, en cambio, parece bastante más simple: si el punto de partida fue un modelo abierto identificable, ocultarlo o diluirlo en el lanzamiento altera por completo la percepción pública del producto. Esa última conclusión es una inferencia periodística apoyada en el contraste entre el anuncio inicial de Cursor y la posterior admisión de Robinson.
Más allá del chisme en X, la polémica de Composer 2 deja una lección más amplia. En un momento en que cada vez más compañías construyen sobre modelos abiertos, la línea entre innovación propia, adaptación legítima y presentación equívoca se vuelve cada vez más sensible. Cursor no quedó bajo fuego solo por usar una base open source; quedó bajo fuego por cómo la presentó.


